Ruby MRI Source Code Idioms #3: Embedded Objects
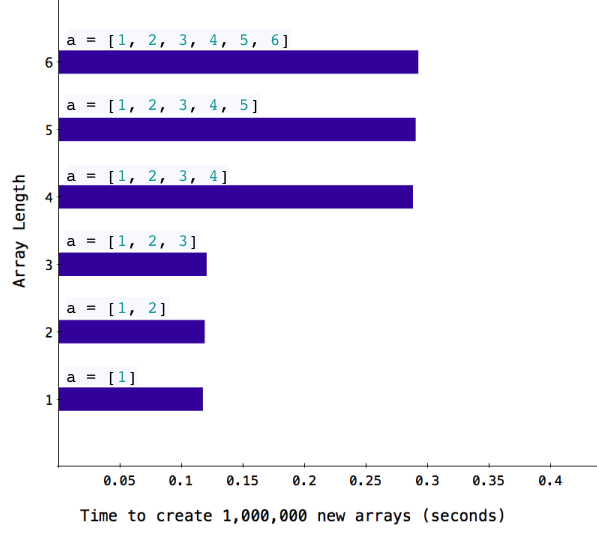
Last year I wrote a post about how the core team optimized Ruby to process shorter strings faster than longer strings. I found that Ruby strings containing 23 or fewer characters are much faster. Why am I bringing this up again now? Well, it turns out this isn’t a single optimization that the core team has added for short strings. Instead, they’ve used the same technique in many other places as well. For example, if you create an array with only one, two or three elements, it’s much faster than if you create an array with four or more elements:
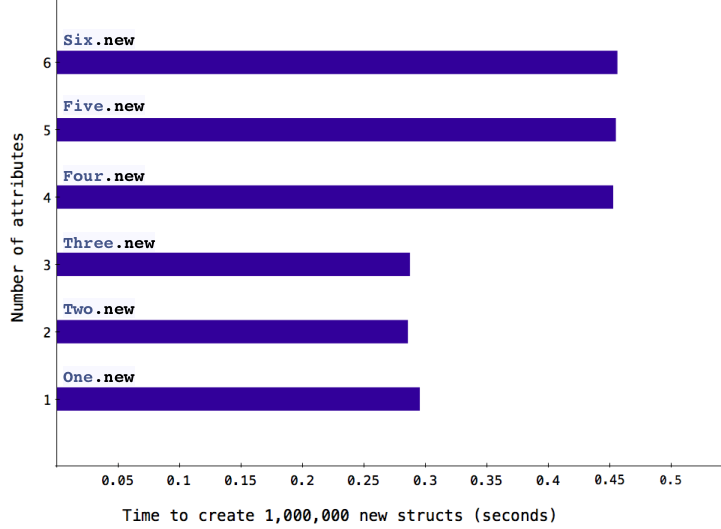
Or if you create a Struct object, it’s much faster when there are three or fewer attributes:

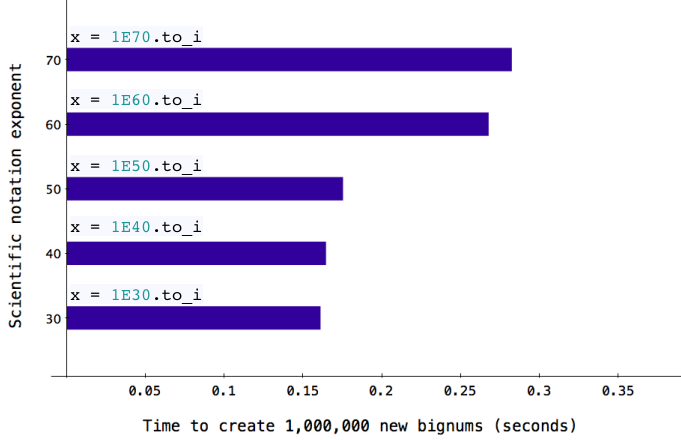
The same pattern also appears if you create large integer values using the Bignum class:
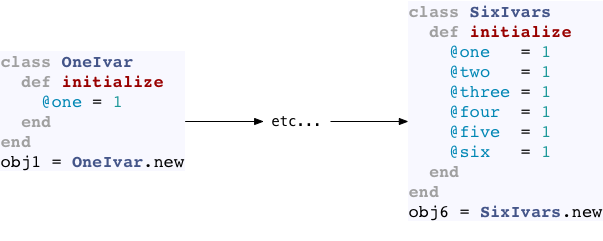
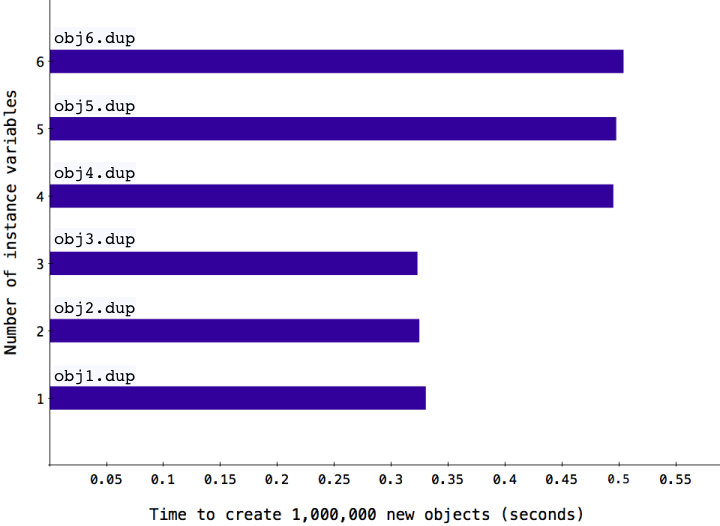
Even your own Ruby objects are faster if they contain three or fewer instance variables:
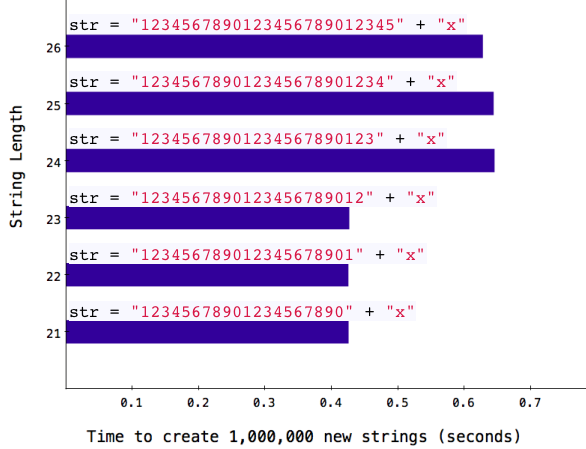
Finally, here’s the data showing the same optimization for Ruby strings that I wrote about last year - you can see strings containing 23 or fewer characters are faster:
So should you stop and refactor all of your code to use small arrays, short strings, and objects with fewer than four instance variables? Of course not! That’s obviously ridiculous.
Also, I’ve exaggerated the performance difference by running these lines of code in a tight loop, executing the same line of code over and over again. In a more realistic Ruby program the speedup produced by using shorter strings or small arrays would be mixed in with many other types of operations and code. The speed of most Ruby applications has more to do with database connections, network latency and other factors. And, of course, if you’re developing a Rails web site - or more generally using lots of different gems - then your own Ruby code is probably a small fraction of the Ruby code used across your entire application. Bizarre refactoring to use fewer instance variables wouldn’t help you much anyway.
Instead, the reason I’m bringing these optimizations to your attention is:
-
...to give you a small taste of all the hard work the Ruby core team has done to speed up your code. The core team has put in countless hours of work to squeeze every bit of performance out of Ruby they could to make your code run faster. To make these optimizations work they had to add many lines of complex, additional C code inside of Ruby.
-
...to make it easier for you to follow the C source code inside of Ruby. If you’re interested in learning how your language actually works internally then you’ll need to understand the coding patterns behind these optimizations.
-
...because it’s fun to see how these things actually work!
A verbose optimization
There are many places within Ruby’s C source code where small objects - the objects corresponding to the shorter bars in the charts above - are handled differently than larger objects. This is such a common pattern that I consider it an MRI idiom. In order to understand how many of the built in functions in the String, Array, Struct, or Bignum classes work you need to understand the coding pattern behind this optimization. And, as we saw above, Ruby also uses this pattern when handling instance variables in your own classes.
I call these smaller, faster objects “Embedded Objects,” based on the name of certain C constants used inside of Ruby. For example, here’s the C code that Ruby uses to create a new array of a certain size or “capacity:”
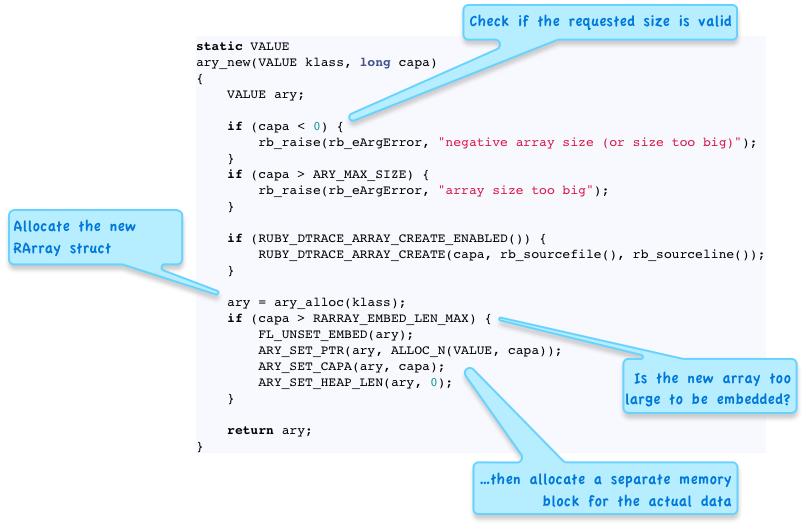
As you can see arrays longer than RARRAY_EMBED_LEN_MAX are handled differently than shorter arrays. What’s the value of RARRAY_EMBED_LEN_MAX? It turns out it is 3. This explains the behavior in the chart above.
Here’s another example - whenever you increase the size of a string, for example by calling String#<< or String#insert, Ruby uses this code:
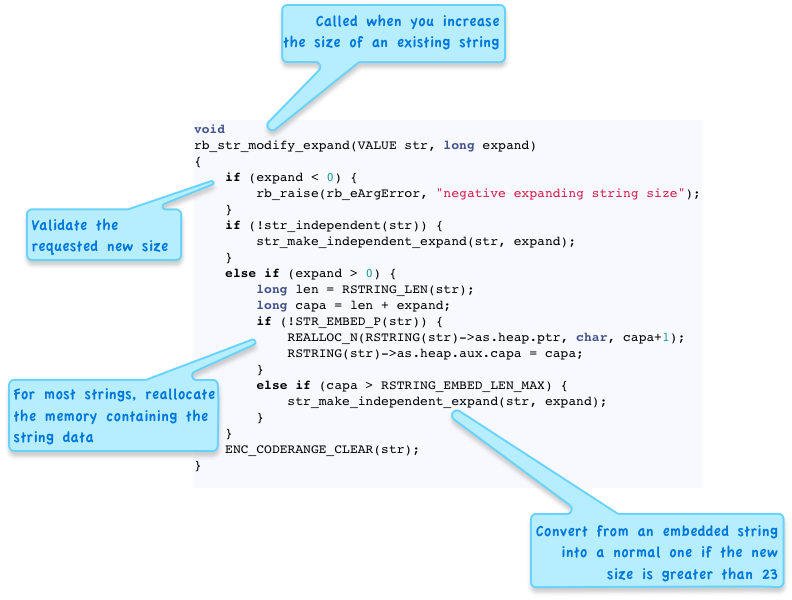
Here again, we can see Ruby handles longer strings differently than shorter strings, using the value RSTRING_EMBED_LEN_MAX. What is this set to? Well, from the performance chart above we know it must be 23.
Finally, here’s the code Ruby uses to create new Struct objects:

Once again you can see structs with fewer than RSTRUCT_EMBED_LEN_MAX members are handled differently than structs with more attributes. What’s the value of RSTRUCT_EMBED_LEN_MAX? It must be 3, based on the chart above.
These are just three simple examples; if you go and look you’ll find that these “EMBED” constants appear in many places inside Ruby’s implementation of these 4 built-in classes, along with the code that handles instance variables in your objects. Each time one of these constants appears, there will also be code the Ruby core team had to write to handle embedded objects differently - to make your code run a few microseconds faster!
To summarize, here are the 5 C constants Ruby uses as a threshold for embedded objects, and their values:

You can find these values in the include/ruby/ruby.h file. As you can see, each of these corresponds to one of the performance pattern you see in the charts above. For the Bignum class, Ruby uses the RBIGNUM_EMBED_LEN_MAX value to keep track of how many BDIGIT structures will fit into a single RBignum structure. Ruby uses these BDIGIT structures to hold large integer values, and allocates more of them as necessary to represent very large integers.
The C “union” keyword
Above I showed a few places where these “EMBED” constants appear in Ruby’s source code, but the most important places the constant appears is in the C structure definitions for these object types. For example, as I explained two weeks ago, Ruby represents every array object using the RArray structure:
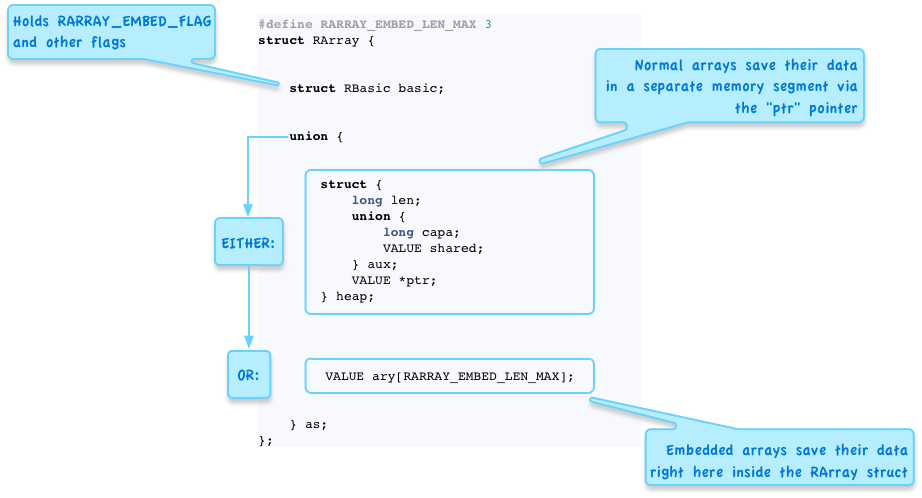
Here I’ve shown the RArray struct separated into two pieces: the top rectangle shows how larger arrays with 4 or more elements save their data, and the lower rectangle shows how shorter array with three or fewer elements work. The key to this is the union keyword, which is a trick you can use in the C language to indicate the same memory segment can be used in more than one way:
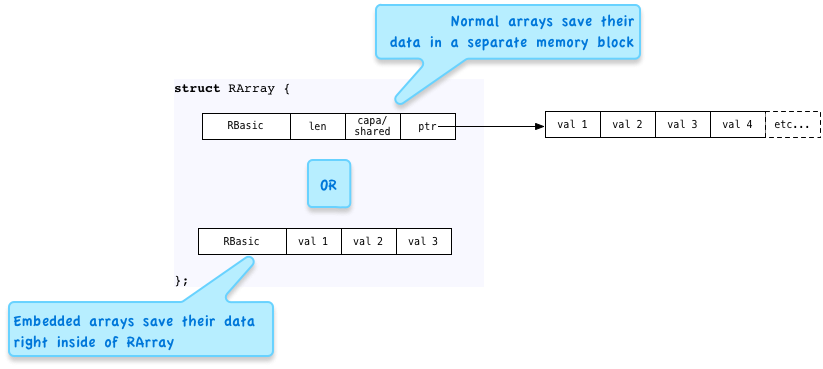
By using the union keyword, the C compiler allows you to access either the values on the top via the heap structure, the first member of the union, or the values on the bottom, inside the ary array, the second member of the union.
Accessing embedded objects via macros
As I also wrote about two weeks ago, Ruby uses a series of C macros to access the data inside an array, string or most other built in object types. The Ruby core team, fortunately, also uses these macros to hide some of the complexity around embedded objects.
To see what I mean, here’s the definition of the RARRAY_PTR macro - Ruby uses this to get a pointer to an array’s elements:
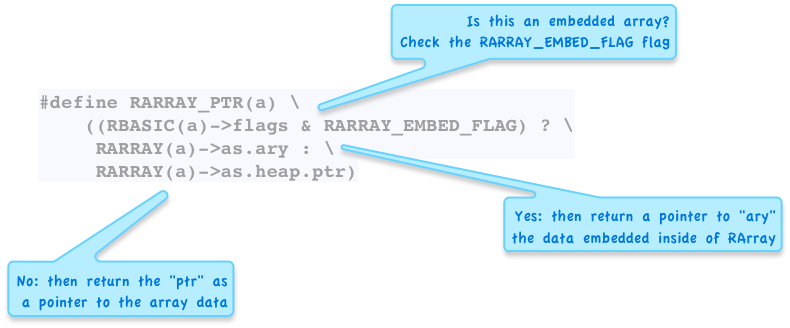
Every time Ruby needs access to the contents of an array, it runs the code found inside this macro: First, it uses a second macro, RBASIC, to get access to some internal flags stored inside the inner RBasic structure. One of these flags is called RARRAY_EMBED_FLAG. If RARRAY_EMBED_FLAG is set, then Ruby knows this array is an embedded object, and therefore looks for the array’s elements in as.ary - or the array located right inside the RArray struct. If RARRAY_EMBED_FLAG is not set, then Ruby looks for the array’s elements in the usual way by following the ptr pointer to another memory block in the heap.
Learn the idiom once and use it many times
As I said above, by learning just a few coding patterns, you can quickly start to understand large parts of Ruby’s internal source code. Since the embedded object pattern is used by five different types of objects, it makes a lot of sense to spend some time learning how it works. By learning a few more MRI idioms, you’ll start to think like a member of the Ruby core team! Stay tuned, next time we’ll look at another common coding pattern used by Matz and his colleagues...


