Never create Ruby strings longer than 23 characters
 |
| Looking at things through a microscope sometimes leads to surprising discoveries |
Obviously this is an utterly preposterous statement: it’s hard to think of a more ridiculous and esoteric coding requirement. I can just imagine all sorts of amusing conversations with designers and business sponsors: “No... the size of this <input> field should be 23... 24 is just too long!” Or: “We need to explain to users that their subject lines should be less than 23 letters...” Or: “Twitter got it all wrong... the 140 limit should have been 23!”
Why in the world would I even imagine saying this? As silly as this requirement might be, there is actually a grain of truth behind it: creating shorter Ruby strings is actually much faster than creating longer ones. It turns out that this line of Ruby code:
str = "1234567890123456789012" + "x"
... is executed about twice as fast by the MRI 1.9.3 Ruby interpreter than this line of Ruby code:
str = "12345678901234567890123" + "x"
Huh? What’s the difference? These two lines look identical! Well, the difference is that the first line creates a new string containing 23 characters, while the second line creates one with 24. It turns out that the MRI Ruby 1.9 interpreter is optimized to handle strings containing 23 characters or less more quickly than longer strings. This isn’t true for Ruby 1.8.
Today I’m going to take a close look at the MRI Ruby 1.9 interpreter to see how it actually handles saving string values... and why this is actually true.
Not all strings are created equal
Over the holidays I decided to read through the the Ruby Hacking Guide. If you’ve never heard of it, it’s a great explanation of how the Ruby interpreter works internally. Unfortunately it’s written in Japanese, but a few of the chapters have been translated into English. Chapter 2, one of the translated chapters, was a great place to start since it explains all of the basic Ruby data types, including strings.
After reading through that, I decided to dive right into the MRI 1.9.3 C source code to learn more about how Ruby handles strings; since I use RVM for me the Ruby source code is located under ~/.rvm/src/ruby-1.9.3-preview1. I started by looking at include/ruby/ruby.h, which defines all of the basic Ruby data types, and string.c, which implements Ruby String objects.
Reading the C code I discovered that Ruby actually uses three different types of string values, which I call:
- Heap Strings,
- Shared Strings, and
- Embedded Strings
I found this fascinating! For years I’ve assumed every Ruby String object was like every other String object. But it turns out this is not true! Let’s take a closer look...
Heap Strings
The standard and most common way for Ruby to save string data is in the “heap.” The heap is a core concept of the C language: it’s a large pool of memory that C programmers can allocate from and use via a call to the malloc function. For example, this line of C code allocates a 100 byte chunk of memory from the heap and saves its memory address into a pointer:
char *ptr = malloc(100);
Later, when the C programmer is done with this memory, she can release it and return it to the system using free:
free(ptr);
Avoiding the need to manage memory in this very manual and explicit way is one of the biggest benefits of using any high level programming language, such as Ruby, Java, C#, etc. When you create a string value in Ruby code like this, for example:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit"
... the Ruby interpreter creates a structure called “RString” that conceptually looks like this:
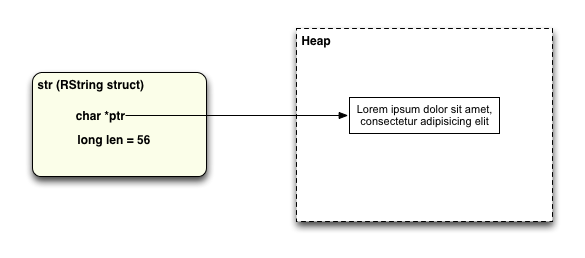
You can see here that the RString structure contains two values: ptr and len, but not the actual string data itself. Ruby actually saves the string character values themselves in some memory allocated from the heap, and then sets ptr to the location of that heap memory, and len to the length of the string.
Here’s a simplified version of the C RString structure:
struct RString { long len; char *ptr; };
I’ve simplified this a lot; there are actually a number of other values saved in this C struct. I’ll discuss some of them next, and others I’ll skip over for today. If you’re not familiar with C, you can think of struct (short for “structure”) as an object that contains a set of instance variables, except in C there’s no object at all - a struct is just a chunk of memory containing a few values.
I refer to this type of Ruby string as “Heap String,” since the actual string data is saved in the heap.
Shared Strings
Another type of string value that the Ruby interpreter uses is called a “Shared String” in the Ruby C source code. You create a Shared String every time you write a line of Ruby code that copies one string to another, similar to this:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str
Here the Ruby interpreter has realized that you are assigning the same string value to two variables: str and str2. So in fact there’s no need to create two copies of the string data itself; instead Ruby creates two RString values that share the single copy of the string data. The way this works is that both RString structs contain the same ptr value to the shared data... meaning both strings contain the same value. There’s also a shared value saved in the second RString struct that points to the first RString struct. There are some other details which I’m not showing here, such as some bit mask flags that Ruby uses to keep track of which RString’s are shared and which are not.
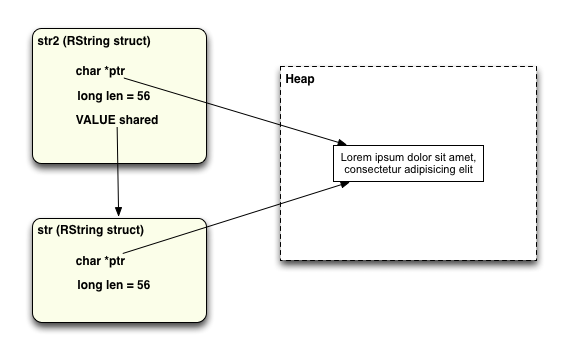
Aside from saving memory, this also speeds up execution of your Ruby programs dramatically by avoiding the need to allocate more memory from the heap using another call to malloc. Malloc is actually a fairly expensive operation: it takes time to track down available memory of the proper size in the heap, and also to keep track of it for freeing later.
Here’s a somewhat more accurate version of the C RString structure, including the shared value:
struct RString {
long len;
char *ptr;
VALUE shared;
};
Strings that are copied from one variable to another like this I call “Shared Strings.”
Embedded Strings
The third and last way that MRI Ruby 1.9 saves string data is by embedding the characters into the RString structure itself, like this:
str3 = "Lorem ipsum dolor"

This RString structure contains a character array called ary and not the ptr, len and shared values we saw above. Here’s another simplified definition of the same RString structure, this time containing the ary character array:
struct RString { char ary[RSTRING_EMBED_LEN_MAX + 1]; }
If you’re not familiar with C code, the syntax char ary[100] creates an array of 100 characters (bytes). Unlike Ruby, C arrays are not objects; instead they are really just a collection of bytes. In C you have to specify the length of the array you want to create ahead of time.
How do Embedded Strings work? Well, the key is the size of the ary array, which is set to RSTRING_EMBED_LEN_MAX+1. If you’re running a 64-bit version of Ruby RSTRING_EMBED_LEN_MAX is set to 24. That means a short string like this will fit into the RString ary array:
str = "Lorem ipsum dolor"
... while a longer string like this will not:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit"
How Ruby creates new string values
Whenever you create a string value in your Ruby 1.9 code, the interpreter goes through an algorithm similar to this:
- Is this a new string value? Or a copy of an existing string? If it’s a copy, Ruby creates a Shared String. This is the fastest option, since Ruby only needs a new RString structure, and not another copy of the existing string data.
- Is this a long string? Or a short string? If the new string value is 23 characters or less, Ruby creates an Embedded String. While not as fast as a Shared String, it’s still fast because the 23 characters are simply copied right into the RString structure and there’s no need to call malloc.
- Finally, for long string values, 24 characters or more, Ruby creates a Heap String - meaning it calls malloc and gets some new memory from the heap, and then copies the string value there. This is the slowest option.
The actual RString structure
For those of you familiar with the C language, here’s the actual Ruby 1.9 definition of RString:
struct RString { struct RBasic basic; union { struct { long len; char *ptr; union { long capa; VALUE shared; } aux; } heap; char ary[RSTRING_EMBED_LEN_MAX + 1]; } as; };
I won’t try to explain all the code details here, but here are a couple important things to learn about Ruby strings from this definition:
- The RBasic structure keeps track of various important bits of information about this string, such as flags indicating whether it’s shared or embedded, and a pointer to the corresponding Ruby String object structure.
- The capa value keeps track of the “capacity” of each heap string... it turns out Ruby will often allocate more memory than is required for each heap string, again to avoid extra calls to malloc if a string size changes.
- The use of union allows Ruby to EITHER save the len/ptr/capa/shared information OR the actual string data itself.
- The value of RSTRING_EMBED_LEN_MAX was chosen to match the size of the len/ptr/capa values. That’s where the 23 limit comes from.
Here’s the line of code from ruby.h that defines this value:
#define RSTRING_EMBED_LEN_MAX ((int)((sizeof(VALUE)*3)/sizeof(char)-1))
On a 64 bit machine, sizeof(VALUE) is 8, leading to the limit of 23 characters. This will be smaller for a 32 bit machine.
Benchmarking Ruby string allocation
Let’s try to measure how much faster short strings are vs. long strings in Ruby 1.9.3 - here’s a simple line of code that dynamically creates a new string by appending a single character onto the end:
new_string = str + 'x'
The new_string value will either be a Heap String or an Embedded String, depending on how long the str variable’s value is. The reason I need to use a string concatenation operation, the + 'x' part, is to force Ruby to allocate a new string dynamically. Otherwise if I just used new_string = str, I would get a Shared String.
Now I’ll call this method from a loop and benchmark it:
require 'benchmark' ITERATIONS = 1000000 def run(str, bench) bench.report("#{str.length + 1} chars") do ITERATIONS.times do new_string = str + 'x' end end end
Here I’m using the benchmark library to measure how long it takes to call that method 1 million times. Now running this with a variety of different string lengths:
Benchmark.bm do |bench| run("12345678901234567890", bench) run("123456789012345678901", bench) run("1234567890123456789012", bench) run("12345678901234567890123", bench) run("123456789012345678901234", bench) run("1234567890123456789012345", bench) run("12345678901234567890123456", bench) end
We get an interesting result:
user system total real 21 chars 0.250000 0.000000 0.250000 ( 0.247459) 22 chars 0.250000 0.000000 0.250000 ( 0.246954) 23 chars 0.250000 0.000000 0.250000 ( 0.248440) 24 chars 0.480000 0.000000 0.480000 ( 0.478391) 25 chars 0.480000 0.000000 0.480000 ( 0.479662) 26 chars 0.480000 0.000000 0.480000 ( 0.481211) 27 chars 0.490000 0.000000 0.490000 ( 0.490404)
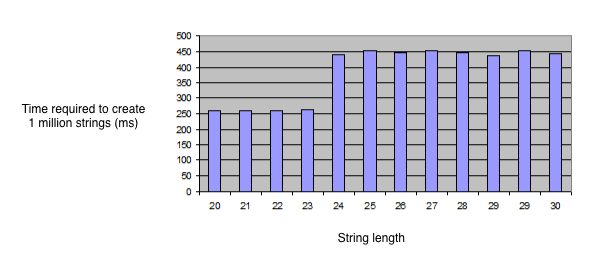
Note that when the string length is 23 or less, it takes about 250ms to create 1 million new strings. But when my string length is 24 or more, it takes around 480ms, almost twice as long!
Here’s a graph showing some more data; the bars show how long it takes to allocate 1 million strings of the given length:
Conclusion
Don’t worry! I don’t think you should refactor all your code to be sure you have strings of length 23 or less. That would obviously be ridiculous. The speed increase sounds impressive, but actually the time differences I measured were insignificant until I allocated 100,000s or millions of strings - how many Ruby applications will need to create this many string values? And even if you do need to create many string objects, the pain and confusion caused by using only short strings would overwhelm any performance benefit you might get.
For me I really think understanding something about how the Ruby interpreter works is just fun! I enjoyed taking a look through a microscope at these sorts of tiny details. I do also suspect having some understanding of how Matz and his colleagues actually implemented the language will eventually help me to use Ruby in a wiser and more knowledgeable way. We’ll have to see... stay tuned for some more posts about Ruby internals!


