Seeing double: how Ruby shares string values
 |
| How many Ruby string values can you see? |
How many times do you think Ruby allocates memory for the “Lorem ipsum...” string while running this code snippet?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str
...or what about while running this snippet?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = String.new(str)
...and this one?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase!
Or this one?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1]
The answers are not what you expect! Both the 1.9 and 1.8 MRI Ruby interpreters use an optimization called “copy on write” to avoid unnecessarily copying large string values. Like I did two weeks ago when I discussed how Ruby 1.9 runs faster with strings containing 23 bytes or less, today I’m going to take a deep dive into Ruby internals to see how the copy on write optimization works. Read on to learn more... and to find out how many strings were allocated by the code snippets above!
Referring to one String object with two variables
Two weeks ago I used this example to illustrate how Ruby shares string values:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str
Here’s a diagram showing how this string value is shared by str and str2:
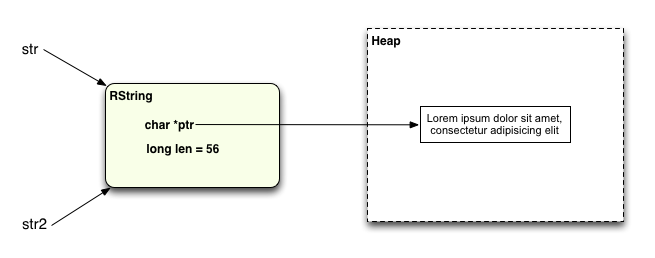
As Evan Phoenix pointed out in a comment on my last post, I was actually incorrect to use this as an example of a shared string. There really isn’t any sharing here at all: instead we just have two Ruby variables pointing to or referring to the same, single RString value.
To find out exactly what is contained in any RString structure, and to prove this is actually what is happening inside the Ruby interpreter, I wrote a simple C extension that will display the hexadecimal address of a given RString value, along with the hexadecimal value of ptr, which is the RString member that points to the actual string data. See my last post for more details on how RString works. I’ve included the C source code for this extension below in the “Appendix” if you’re interested in the details.
To use my C extension, I just need to require it and create an instance of the Debug class and use it by calling display_string as follows:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Running this code I get the following output:
$ ruby test.rb str: DEBUG: RString = 0x7fd64a84f620 DEBUG: ptr = 0x7fd64a416fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fd64a84f620 DEBUG: ptr = 0x7fd64a416fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56
No surprise: You can see there’s a single RString structure at hexadecimal address 0x7fd64a84f620, which both str and str2 point to. And ptr, the location of the actual string data for each variable, is also the same: 0x7fd64a416fe0. Obviously str and str2 both refer to the same Ruby string object.
Sharing one string value between two String objects
 |
| MRI Ruby will not copy string values unnecessarily |
However, Ruby does actually share string values. In my last post I should have used the following code as an example instead:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup
Now calling the Object.dup method will create a second RString structure that shares the same string data, since a second String object is created. I could also have used String.new like this:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = String.new(str)
Here’s what we have now:
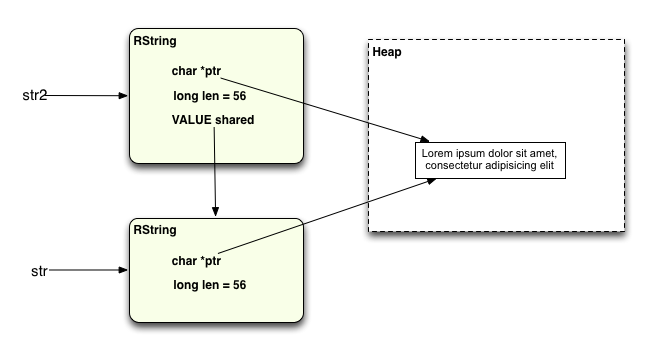
This is a “Shared String:” two RString structures that share the same string data. You can see there’s a single copy of the actual string data, and that both RString structures have the same value for ptr and len. Also, the shared value in str2 is a pointer back to the RString structure that it is sharing with. The same pattern could be used for 3, 4 or more RString structures that all share the same string value.
The obvious benefits here are:
- You save memory since there’s only one copy of the string data, not two, and:
- You save execution time since there’s no need to call malloc a second time to allocate more memory from the heap.
To prove this is what’s happening with RString after calling Object.dup, I’ll call my display_string code again as follows:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Running this:
$ ruby test.rb str: DEBUG: RString = 0x7fdd2904f4a8 DEBUG: ptr = 0x7fdd28d16fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fdd2904f430 DEBUG: ptr = 0x7fdd28d16fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56
Here you can see there are now two different RString structures, just like the picture above, with these two addresses: 0x7fdd2904f4a8 and 0x7fdd2904f430. But the important detail to notice here is that the value of ptr, the hexadecimal address of the actual string data (0x7fdd28d16fe0), is the same in both cases!
Remember, the concept of a shared string is a purely internal optimization. As a Ruby developer you don’t need to know that there really is only one copy of the string data in memory, and that both objects are sharing it. Just think of them as two separate string values - most of the time you don’t need to think about this.
Note: this optimization doesn’t actually happen if the string value is 23 bytes or less, using embedded strings, since in that case the string data is actually saved right inside each RString structure. But for short strings sharing wouldn’t have saved us much time or memory, and by saving the string data inside the RString structure Ruby can save even more time and memory. The shared string optimization helps you the most when you are working with very large string values that contain thousands or even millions of bytes, for example. In that scenario it’s nice to know that Ruby won’t copy around all that string data whenever you copy a string value from one Ruby String object to another.
Copy on write
Obviously there’s more to the story here. How can two separate String objects share the same value, when I’m free to change one or both of their values? For example, suppose again I have two separate strings:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup
What happens if I now modify the value of one of the two String objects, for example like this:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase!
Now the two values are different:
puts str => "Lorem ipsum dolor sit amet, consectetur adipisicing elit" puts str2 => "LOREM IPSUM DOLOR SIT AMET, CONSECTETUR ADIPISICING ELIT"
Obivously these two strings no longer share the same value. What happened? Well first at the moment that you call upcase! the Ruby interpreter makes a new copy of the string heap data for str2 like this:
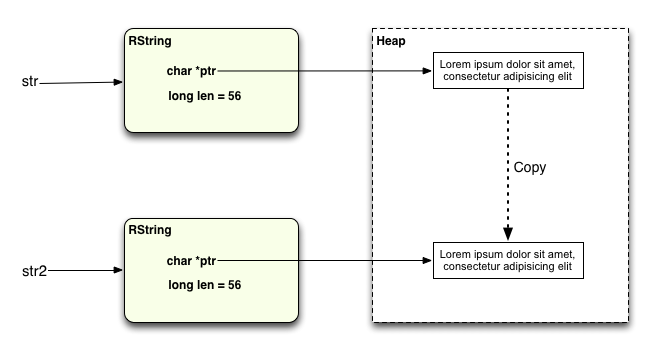
And then it performs the upcase! operation on that new copy:
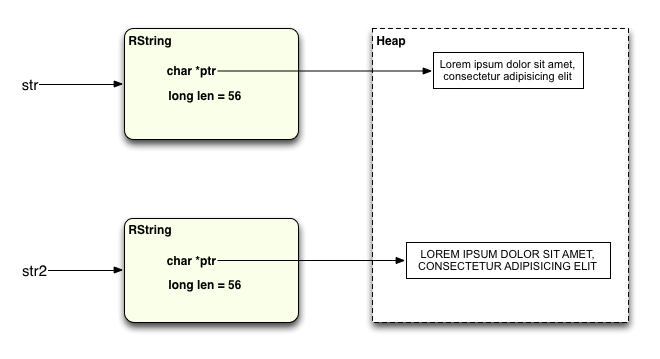
As Simon Russell explained in a comment on my last post, this algorithm is referred to as “copy on write,” meaning that the two string objects actually share the same string value until the very last moment when this is possible, while the two values are still the same. Then just before one of them changes, Ruby make a separate copy of the string and applies the write operation (upcase! in this example) to the new copy.
Let’s take a look at the two RString values again using my display_string code:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase! puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Running this I get:
$ ruby test.rb str: DEBUG: RString = 0x7fa46b04ef90 DEBUG: ptr = 0x7fa46ac8b1d0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fa46b04ef68 DEBUG: ptr = 0x7fa46ac2e560 -> "LOREM IPSUM DOLOR SIT AMET, CONSECTETUR ADIPISICING ELIT" DEBUG: len = 56
You can see that the two RString structure now have different values for the ptr member - they are no longer shared strings. All of this happens transparently to the Ruby developer.
How copy on write works with String.slice
Following Robert Sanders’ suggestion in another comment on my last post, I decided to take a look at how the copy on write operation works with another Ruby String method: slice. What I found was that most of the time a second copy of the string is made for the slice operation. For example:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..25]
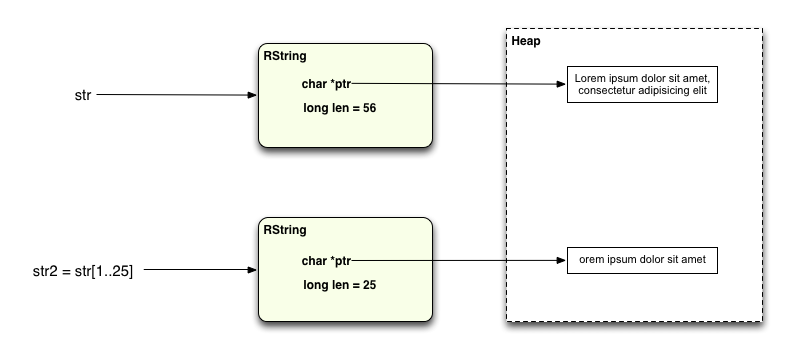
However, often the substring is a single character or just a few characters from the target string:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..4]
In this case the new string is less than 24 characters long, so there’s no need to call malloc again to allocate more memory. The short substring is just saved into the new RString object:
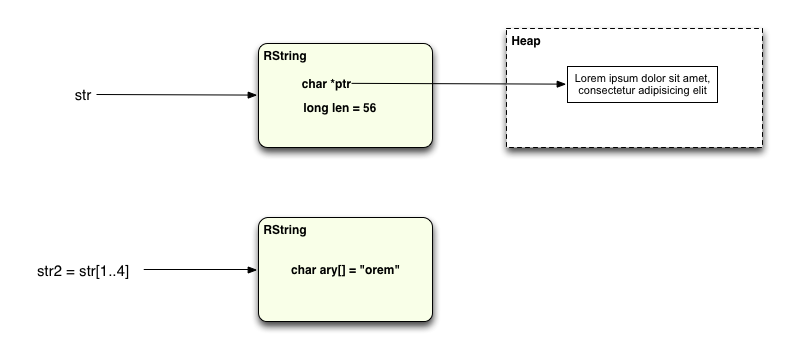
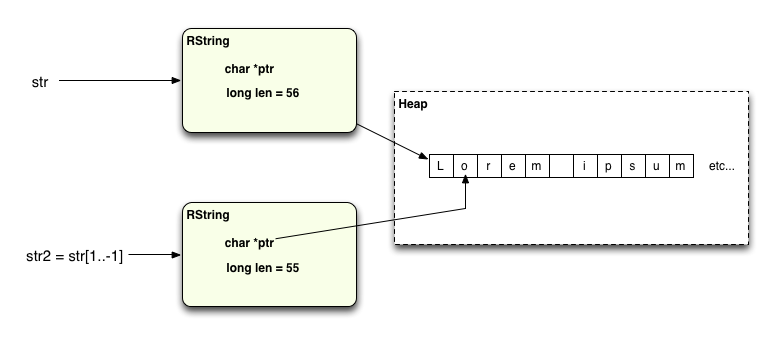
However, one interesting optimization I found in the MRI Ruby string implementation was that if you happen to take a substring that includes all of the remaining characters up to the end of the original string, like this:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1]
... then Ruby will continue to share the same string data! What it does is set the ptr value of str2 to point at the same string data, but advanced forward in memory by the proper number of bytes to return the desired substring:
Let's test it out using the same debug code:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1] puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Now I see that the value of ptr for str2 is set to ptr+1 from str!
$ ruby test.rb str: DEBUG: RString = 0x7fb71b04efa0 DEBUG: ptr = 0x7fb71ad007a0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fb71b04ef78 DEBUG: ptr = 0x7fb71ad007a1 -> "orem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 55
What this means for Ruby developers using str.slice or the str[a..b] variants is:
- Creating a substring 23 characters or less is fastest
- Create a substring running to the end of the target string is also fast (the str[x..-1] syntax), and
- Creating any other long substring, 24 or more bytes, is slower.
Conclusion
As a Ruby developer you should feel comfortable copying long string values from one String object to another, even when the string values are quite large. The MRI Ruby development team has done a lot of great work to insure the interpreter does not unnecessarily allocate memory and copy the contents of large strings. Ruby programs are often string intensive and this important optimization can have a dramatic impact on both speed and memory consumption.
However, remember that modifying a string value will force Ruby to make a new copy of the string data at the time you actually modify it. Most of the time this is unavoidable... if you need to modify a string then you need to modify it. However, understanding how Ruby implements copy on write can help you be smarter while writing ruby code that does need to handle large strings and possibly modify them.
Appendix: The “display_string” C extension
Here’s the C extension code I used above, in case anyone is interested:
#include "ruby.h" static VALUE display_string(VALUE self, VALUE str) { char *ptr; printf("DEBUG: RString = 0x%lx\n", str); ptr = RSTRING_PTR(str); printf("DEBUG: ptr = 0x%lx -> \"%s\"\n", (VALUE)ptr, ptr); printf("DEBUG: len = %ld\n", RSTRING_LEN(str)); return Qnil; } void Init_display_string() { VALUE klass; klass = rb_define_class("Debug", rb_cObject); rb_define_method(klass, "display_string", display_string, 1); }
What this C code does is create a new Ruby class called Debug that contains a single method called display_string. The method takes a single string argument and then displays the address of the RString structure, as well as the address of the actual string data, along with its length using printf statements.
To build and use this extension code, first paste the C code from above into a file called “display_string.c” and then create a file called “extconf.rb” in the same directory containing these two lines:
require 'mkmf' create_makefile("display_string")
Then create a C Makefile using this command:
$ ruby extconf.rb
And finally compile the C code like this:
$ make
Now you can use the Ruby snippets from above if your Ruby code is located in the same directory.


