Saving a Tree in Postgres Using LTREE

In my last post, I showed you how to install and enable a Postgres extension called LTREE. LTREE allows me to save, query on and manipulate trees or hierarchical data structures using a relational database table. As we’ll see, using LTREE I can count leaves, cut off branches, and climb up and down trees easily - all using SQL right inside my application’s existing Postgres database!
But trees are natural, haphazard, branching structures with countless leaves, while database tables are man-made rectangles full of numbers and text. How can I possibly save a beautiful tree structure into an ugly, boring database table?
Path Enumeration
Let’s return to the example tree from the first post in this series:
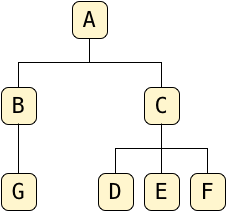
The LTREE extension uses the path enumeration algorithm, which calls for each node in the tree to record the path from the root you would have to follow to reach that node.
For example, to find G starting from A, the root, I would move down to B, and then down again to G:
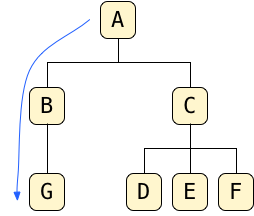
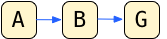
So the path to G is:
Here’s another example:
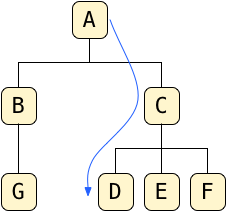
This time I’ve traced a path from A to D, via C. So the path of D is:
Saving Tree Paths Using LTREE
To use LTREE, I need to create a column to hold these paths. For my example tree, I’ll use the same table I did before, but instead of the parent_id column I’ll use a path column:
create table tree(
id serial primary key,
letter char,
path ltree
);
create index tree_path_idx on tree using gist (path);
I chose the name path; I could have picked any name here. However, notice the path column uses a Postgres data type called ltree - the LTREE extension provides this special new type. And also notice I created a special gist index on the path column; more on this later!
Next, I save the path of each tree node into the path column, encoded as a series of strings joined together by periods. For example to save the path of G into my table I use this insert statement:

And to save the path to node D I write:

Following this pattern, I can save my entire tree using these insert statements, one for each node in my tree:
insert into tree (letter, path) values ('A', 'A');
insert into tree (letter, path) values ('B', 'A.B');
insert into tree (letter, path) values ('C', 'A.C');
insert into tree (letter, path) values ('D', 'A.C.D');
insert into tree (letter, path) values ('E', 'A.C.E');
insert into tree (letter, path) values ('F', 'A.C.F');
insert into tree (letter, path) values ('G', 'A.B.G');
The root node, A, contains the simplest path A. Its two child nodes, B and C, use paths A.B and A.C; the child nodes under C use paths A.C.D, A.C.E, etc. You get the idea.
The Ancestor Operator: @>
Now for the fun part: LTREE provides a series of new SQL operators that allow me to query and manipulate tree data structures. The most powerful of these is @>, the “ancestor” operator. It tests whether one path is an ancestor of another.
Returning to my question from the first post in this series, what if I needed to know how many children A had, recursively? That is, what if I needed to count its children, grandchildren, great-grandchildren, etc.? Earlier we saw that using a parent_id column this would require an ever increasing number of SQL statements:
select count(*) from tree where parent_id = ID; select count(*) from tree where parent_id in (CHILD IDs); select count(*) from tree where parent_id in (GRANDCHILD IDs); select count(*) from tree where parent_id in (GREAT-GRANDCHILD IDs); select count(*) from tree where parent_id in (GREAT_GREAT-GRANDCHILD IDs); etc.
@> solves this problem for us. I can now recursively count the total number of nodes under any given parent like this:
select count(*) from tree where PARENT-PATH @> path;
In my example, this SQL would return the number of nodes, recursively, under the root node A:
select count(*) from tree where 'A' @> path; count ------- 7 (1 row)
LTREE counts the parent node itself, so the total count is 7, not 6. That is, A @> A evaluates to true. Another example; this returns the count of tree nodes under and including C:
select count(*) from tree where ‘A.C' @> path; count ------- 4 (1 row)
Or I could have written these predicates in the opposite order using <@:
select count(*) from tree where path <@ 'A'; select count(*) from tree where path <@ 'A.C';
As you can see, the <@ and @> operators treat the path column, the column I defined with the ltree data type, as simple strings. But there’s some magic going on here: The path values are not simple strings. Although I typed them in as strings, <@ and @> efficiently determine whether or not one path is an ancestor of another.
And the @> ancestor operator is just one way of using ltree columns; the LTREE extension provides a long list of powerful operators and functions! For a complete list, see https://www.postgresql.org/docs/current/static/ltree.html.
In my next post, I’ll explore more of these functions and show you how to perform some tree operations that I’ve found useful.
Maybe You’re Not Impressed
However, thinking about the path strings for a moment, it’s fairly obvious whether one path is an ancestor of another. For example, it’s clear that A and A.C are ancestors of A.C.D, while A.B is not. In fact, it looks like all the @> operator does it check whether the string on the left (the ancestor) is a prefix or leading substring inside the string on the right (the descendant).
In fact, you might not be very impressed by LTREE, so far. The @> operator seems like a fancy way of performing a simple string operation. I could have written SQL code to determine that A is an ancestor of A.C.D myself. I probably would have used one of Postgres’s many string functions to achieve this, maybe something like this:
select count(*) from tree where strpos(path::varchar, 'A') = 1
Postgres would calculate the answer for my 7-node example tree very quickly. But to calculate this count, internally Postgres would have to iterate over all the records in my table (this is called a full table scan or sequence scan in DB jargon) and calculate the strpos function on each row. If my tree had thousands or millions of rows, then this SQL statement would take a long time to finish.
Enabling the Real Magic: Using a GiST Index with LTREE
The power of the @> operator is that it allows Postgres to search efficiently across an entire tree using an index. Saying this in a more technical way: The @> operator integrates with Postgres’s GiST index API to find and match descendant nodes. To take advantage of this technology, be sure to create a GiST index on your ltree column, for example like this:
create index tree_path_idx on tree using gist (path);
What is a “GiST” index? How does it help LTREE find and count tree nodes efficiently? Read the last post in this series to find out. There I describe the Generalized Search Index (GiST) project, explore the Computer Science behind GiST and look at how LTREE uses GiST to make fast tree operations inside of Postgres possible.
What’s Next?
But before we dive into LTREE’s internal implementation, first we should see what else LTREE can do. So far I’ve shown you how to count descendant tree nodes. Tomorrow in my next post, Manipulating Trees Using SQL and the Postgres LTREE Extension, I’ll show you how to use other LTREE’s operators and functions to work with tree data.


