Using Rake to Generate a Blog

Last year I needed to replace the software I use to serve this web site. Instead of just using Jekyll, Middleman, Nanoc or one of the many other available options, I decided to implement my own custom blog software. After a fair amount of work, I was able to implement a static blog site generator using only Rake and a handful of simple Ruby classes. Although it took a bit longer, it was a lot of fun and I learned a few tricks which I’d like to pass along today.
I first got the idea of using Rake as a static site generator from a presentation called Power Rake, given by the late Jim Weirich at GORUCO 2012. This was one of the first Ruby conferences I had ever attended, and was also the first time I had ever seen Jim speak in public. It still stands out in my memory as one of the best conference presentations I've ever seen. Funny, engaging, interesting, but most of all genuine, Jim had me and the rest of the audience enthralled as he talked about Rake, his Ruby reinterpretation of the old C make utility from the 1970s.
The key idea behind using Rake to generate a static site is to generate and manipulate files using Rake file tasks. What are file tasks? How are they different from standard Rake tasks? To find out watch Jim’s presentation, or read an excellent series of articles and screencasts by Avdi Grimm. Today I’ll explain how I used Rake to create this blog. But first, let’s review what a blog really is.
A Blog or a Static Web Site?
Most of the blogs in the world consist of a few dynamically generated web pages served by either wordpress.com or blogger.com. To be honest, I should just use one of these two free services for my site as well. However, I have a few years worth of markdown files that contain all of my old content which would be a hassle to import into whatever format Wordpress or Google uses. Plus using these sites would be no fun at all; instead, I was looking for an excuse to write some Ruby code and to learn more about Rake.
What I really needed was an automated process for converting my markdown source files into a series of static HTML files that were navigable using URL patterns that readers expect. That is, I wanted a Rake task that would do this:
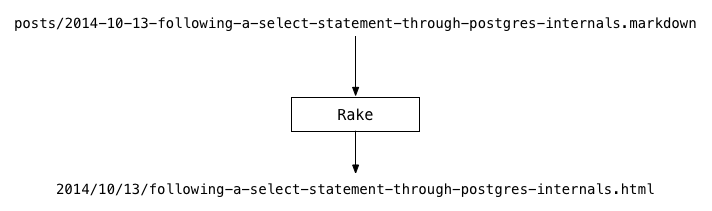
On the top is one of my markdown files; on the bottom is the HTML version. I needed a way to generate the bottom file from the top one. I needed to write a Rake task that would iterate over all of the markdown files in the “posts” directory, and generate the corresponding HTML files in the proper target directory. The markdown file name (“posts/2014-10-13-…”) was a naming convention I used to stay organized. However, the name and path of the HTML file was what readers would see in the post’s URL online - for example: https://patshaughnessy.net/2014/10/13/following-a-select-statement-through-postgres-internals. This was a problem well suited to Rake file tasks, because they allow you to create a series of dependencies between source and target files.
But before I was ready to use file tasks, I needed to use a few tricks to make those tasks easier to write.
Iterating Over Files Using Rake::FileList
Ruby objects are easier to work with than text files are, so the first thing I decided to do was to write a Ruby class that represented one of my markdown files. I called it Post because each markdown file represented a single blog post.
Next, I needed to create a post object for each of the files in the posts directory, by listing the files and iterating over them. It turns out Rake provides a very simple way to do this: the Rake::FileList class. To quote the documentation:
A FileList is essentially an array with a few helper methods defined to make file manipulation a bit easier.
I like things that are easier. Here’s how I used FileList:
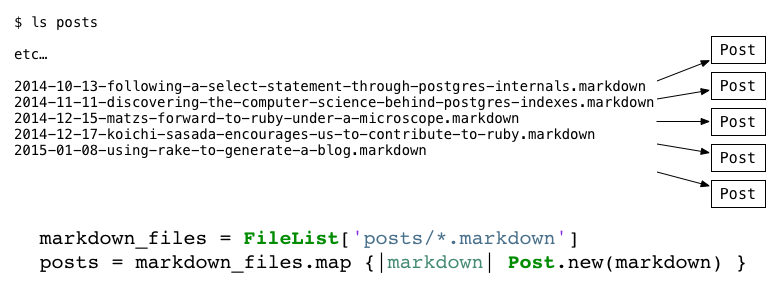
On the left are my markdown files with the corresponding post objects on the right. My code above first created a FileList, using the posts/*.markdown pattern. You can think of the FileList as an array of files that match the given pattern. Once I had this array, I mapped the array to a second array of ruby objects using Enumerable#map.
Blog Post Routing
Now that I had a Post object for each source markdown file, I could add methods to the Post class to make manipulating the markdown files easier. Most importantly, what I needed to know for each markdown file is where its HTML should go in the generated site. That is, I needed to know the URL of the post:

This did the trick. The date and title methods parsed some metadata values I saved in the markdown file along with the text. The url method returned a string using the year/month/day pattern most people are familiar with. The slugize method removed characters from the title that weren’t compatible with URL strings. As I explained earlier, the URL is also the file system path for each post’s HTML file: The single line of code above mapped the posts to an array of strings, each one the path to an HTML file, the URL of that post appended with a file extension.
Grouping Two Arrays Together
Now I had two arrays: Post objects and HTML file paths. I was almost ready to write a Rake file task that would convert the posts into HTML files. But, as you'll see in a minute, writing a file task requires two files: a source file and a target file. Somehow I needed to convert these two separate arrays into a single array of pairs, like this:
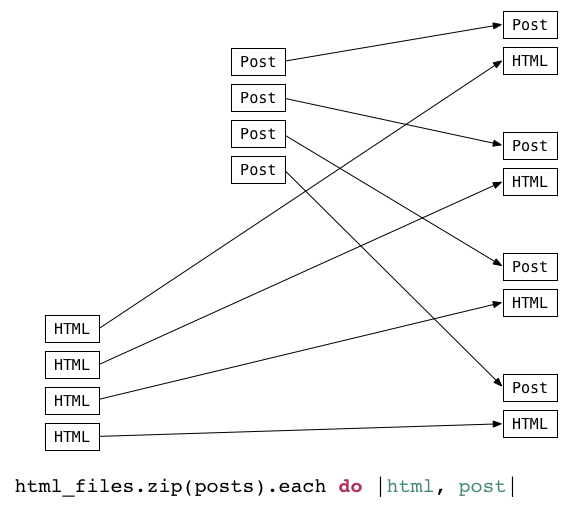
As you can see, Ruby’s Enumerable#zip method was perfect solution. It yielded object pairs, one object taken from the receiver (html_files) and the other object taken from the argument (posts). If you pass in 2, 3 or more arguments, it will yield triplets, quadruplets or n-tuples to the block instead. I first learned about zip from Jim Weirich’s 2012 Power Rake presentation; he used it in his static web site example in a very similar way. Of course, you can use zip to process multiple arrays for any purpose. It’s one of Ruby’s most beautiful features I think.
Writing Rake File Tasks
As you probably know, a standard Rake task runs when you execute the task directly, or when you run another task that depends on it. A file task, however, will only execute the Ruby code inside the block if:
- The source file is newer than the target file, or
- The target file doesn’t exist at all.
This behavior is ideal for generating a static web site, or for any other job that requires generating a file from another file. Rake will build the target file for the first time if it doesn’t exist, or update it if the source file has changed.
Now that I had pairs of HTML paths and Post objects, it was easy for me to write a file task using one of these pairs. Here’s what I came up with:

By calling file inside of the zip block, I created a file task for each one of the paths in html_files. Now if I created a single, standard Rake task that depended on the array of html file paths, I could test whether any or all of the HTML files needed to be generated:
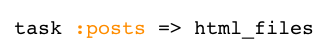
Now I could generate all of my blog posts with one command: rake posts!
Rendering Each Post Using ERB
What did the code inside the file task do? It generated the HTML file for a single post using ERB, using a method I wrote called Layout#render. If you’re interested, here’s the Layout class (github):
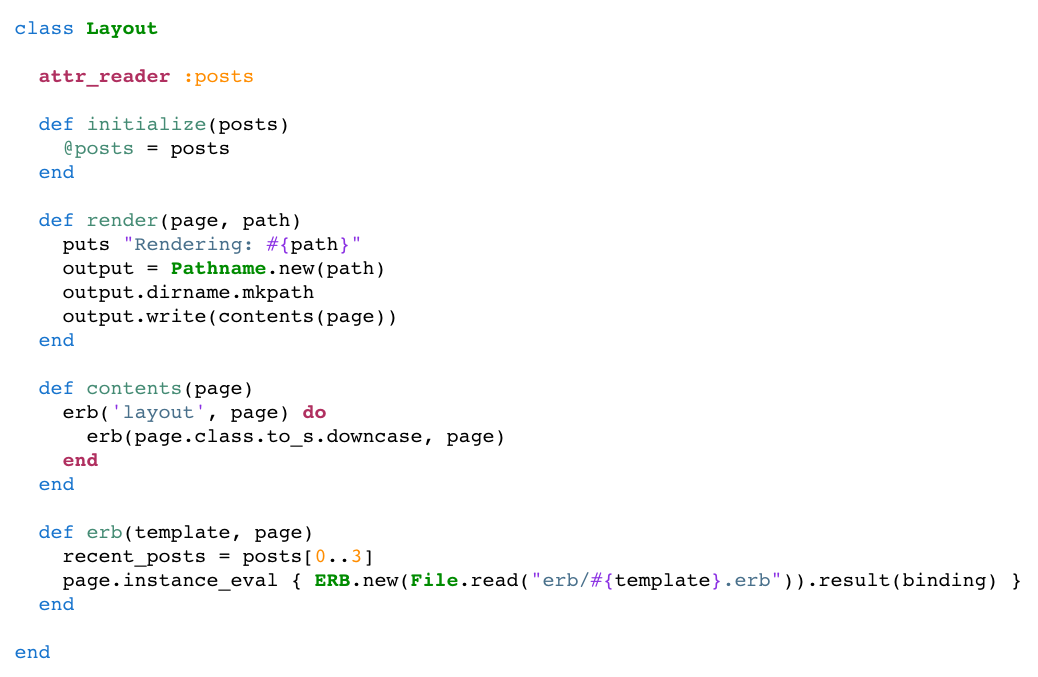
I won’t explain this line by line, but there were a couple of interesting tricks here also. First, the contents method used nested calls to ERB to render a page layout surrounding the post, along with the article text itself. This required I call yield somewhere inside my layout.erb file in just the same way I would in application.html.erb for a Rails app.
The complex line of code at the bottom that uses instance_eval and binding seems impossible to understand at first. But actually it’s fairly standard boilerplate Ruby metaprogramming code that evaluates the ERB template in the context of the page object and the current method.
Let’s take a closer look at this:
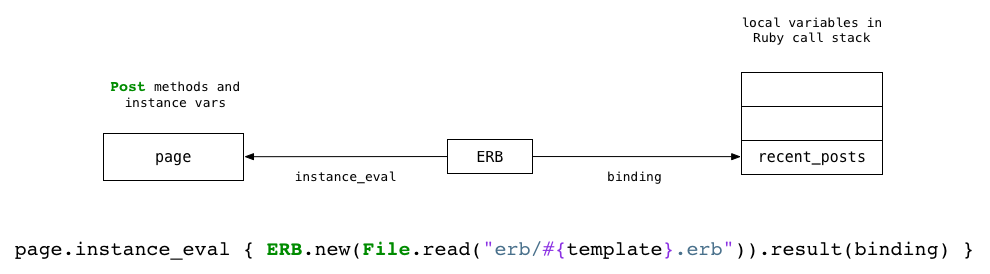
On the left I show the the page object, an instance of the Post class, in the center the code running the ERB transformation, and on the right the Ruby call stack.
The arrow from ERB going to the left represents the use of instance_eval. This method, built into the Ruby language, resets the self pointer to the receiver or the page object in this example. This allows the ERB code to access the instance variables of the page object and the methods of the Post class.
The arrow from ERB going to the right, in turn, represents the call to binding. The binding method, also part of the Ruby core language, refers to the current Ruby stack frame allowing the ERB code to access all of the local variables present there, such as recent_posts.
My Rakefile
Of course, I’m glossing over some other important details here, such as generating the index or home page, the RSS feed and a few other things. For reference, here’s my entire Rakefile (github):

You can see the call to Layout#render and the rake :posts task I described above. Here are some other coding details, if you’re interested:
-
After creating the posts array, I sort it by date, reversed.
-
I generate the home page using another file task: index.html, and a HomePage class.
-
I generate the RSS in a similar way using a third file task: index.xml, and a Feed class.
Ideas, Not Code
If you’re interested in using this code for your own site, it’s on github. However, I wouldn’t recommended using it: It’s always a better idea to use a well tested, robust free service such as wordpress.com or Jekyll.
Instead of using this code, use the ideas behind it! Take the time to use Rake::FileList and Rake file tasks in whatever application you’re working on. And please take the time to watch the PowerRake presentation. You’ll learn more about one of Ruby’s most powerful tools - and you’ll be able spend some time with Jim. Jim’s bright personality and sense of humor can live on in our memory, at least.


