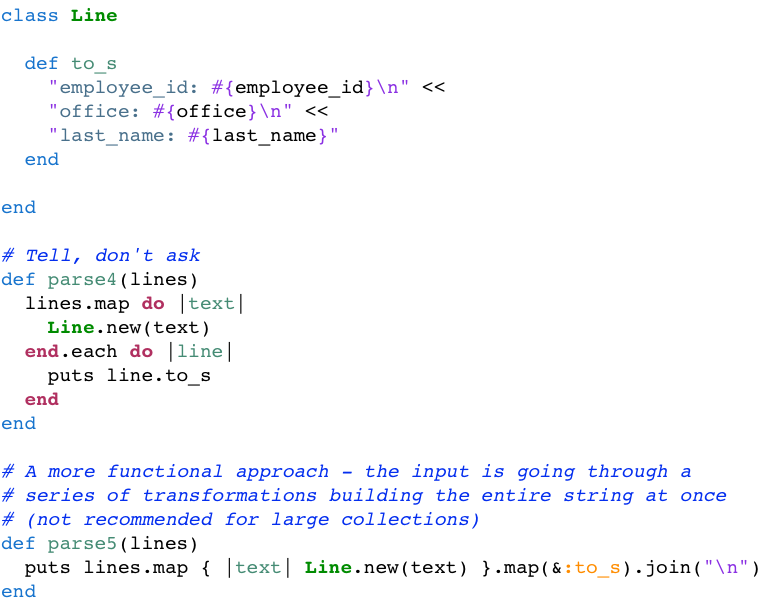
Using a Ruby Class To Write Functional Code
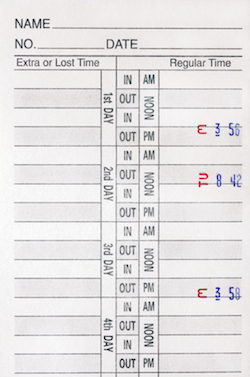 The time sheets I used at my first programming
The time sheets I used at my first programming
job in the Summer of 1986 looked just like this.
Recently I’ve been spending some of my free time studying Clojure and Haskell.
I’ve been learning how a program built with a series of small, pure functions
can be very robust and maintainable. However, I don’t want to give up on Ruby.
I want to keep the expressiveness, beauty and readability of Ruby, while
writing simple functions with no side effects.
But how can this be possible? Unlike functional languages, Ruby encourages you
to hide state inside of objects, and to write functions (methods) that have
side effects, modifying an instance variable for example. Isn’t using an object
oriented language like Ruby, Python, or Java a decision to abandon the benefits
of functional programming?
No. In fact, a couple of weeks ago Ruby’s object model helped me refactor one
confusing function into a series of small simple ones. Today I’ll show you what
happened, how using a Ruby class helped me write more functional code.
Parsing Timesheet Data
Let’s suppose you are a ScrumMaster™ and want to make sure your team of
developers, including me, is putting in enough hours on your project (instead
of taking long lunches or writing blog posts). For example, suppose I report my
hours like this:

You could parse my timesheet data using this simple Ruby program:

This is simple enough to understand and works fine. parse1 is small function; if you remove the calls to puts
it only contains 3 lines of code, two simple calls to split. How could this be
any simpler?
A First Pass at a Functional Solution
Next you decide to look for a more functional solution by asking Ruby for what
you want, instead of telling it what to
do.
You try to break the problem up into small functions that return what you need.
But what functions should you write? What values should they return? In this
simple example, the answer is obvious: you can write a function to parse each
value in the timesheet data.

You have divided the problem up into small pieces. Each function will return a
predictable value based on some input and doesn’t have any side effects. These
will be pure functions: They will always return the same result given the same
arguments. You know that if you pass a line from my timesheet, last_name will always return “Shaughnessy.” You’ve turned
the problem around; you’ve phrased the problem as a series of questions rather
than as a list of instructions.
Refactoring parse1 above, you implement the
functions, at least in a somewhat verbose and ugly fashion:

Testing Pure Functions
As a Certified ScrumMaster™, you believe in TDD and other extreme
programming practices. Originally, while writing parse1 above, it didn’t even occur to you to write tests
(and if it had, it would have been very difficult). However, now after
breaking the problem up into a series of functions, it seems natural to write
tests for them.
Next, you express your expectations for these functions using Minitest specs,
for example:

Because the functions are small, the tests are small. Because the tests are
small, you actually take the time to write them. Because the functions are
decoupled from each other, it’s easy for you to decide which tests to write.
To your surprise, you actually find a bug!
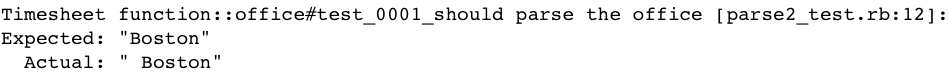
Earlier in parse1, the extra space was lost in the
puts output and you didn’t notice it. Separating this into a small function and
carefully testing it revealed a minor problem. You adjust two of the functions
to remove the extra space:

Pushing Ruby Out Of Its Comfort Zone
You’re happy with your new tests. Ruby allowed you describe the behavior of the
functions in a very natural, readable way. Ruby at its best. As an added bonus,
the tests now also pass!
However, your functions aren’t so pretty. There is a lot of obvious
duplication: The office, employee_id and last_name
functions all call line.split(','). To fix this, you
decide to extract line.split(',') into a separate
function, removing the duplication:

This doesn't look any better; in fact, there’s a deeper problem here. To see
what I mean let’s refactor parse1 from earlier to use
our new functions:

This is clean and easy to follow, but now you have a performance bug: Each time
around the loop, your code passes the same line to employee_id, office and last_name. Now Ruby will call the values function over and
over again. This is unnecessary and needless; in fact, our original parse1 code didn’t have this problem. By introducing
functions we have slowed down our code.
However, because these are simple, pure functions, you know they will always
return the same value given the same input argument, the same line of text in
this example. This means theoretically you can avoid calling split over and over again by caching the results.
At first, you try to cache the return value of split
by using a hash table like this:

This looks straightforward: The keys in split_lines
are the lines and the values are the corresponding split lines. You use Ruby’s
elegant ||= operator either to return a cached value
from the hash or actually call split, updating the
hash.
The only problem with this is that it doesn’t work. The code inside of the
values function can’t access the split_lines hash, located outside the method. And if you
move split_lines inside of values, it would become a
local variable and not retain values across method calls.
To work around this problem you could pass the cache as an additional argument
to values, but this would make your program even more
verbose than it is now. Or you could create the values method using define_method, instead of def,
like this:

This confusing Ruby syntax allows the code inside of the new values method to
access the surrounding scope, including the hash table.
However, taking a step back, something about your program now feels wrong.

Instead of making your code simpler and easier to understand, functional
programming has started to make your Ruby code more confusing and harder to
read. You’ve introduced a new data structure to cache results, and resorted to
confusing metaprogramming to make it work. And your functions are still quite
repetitive.
What’s gone wrong? Possibly Ruby isn’t the right language to use with
functional programming.
Introducing a Ruby Class
Next, you decide to forget all about functional programming and to try again by
using a Ruby class. You write a Line class,
representing a single line of text from the timesheet text file:

And you decide to move your functions into the new Line class:

Now you have a lot less noise. The biggest improvement is that now there’s no
need to pass the line of text around as a parameter to each function. Instead,
you hide it away in an instance variable, making the code much easier to read.
Also, your functions have become methods. Now you know all the functions
related to parsing lines are in the Line class. You
know where to find them, and more or less what they are for. Ruby has helped
you organize your code using a class, which is really just a collection of
functions.
Continuing to simplify, you refactor the value method at the bottom to remove
the confusing define_method syntax:
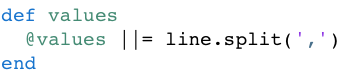
Now each instance of the Line class, each line of text you program uses, will
have its own copy of @values. By using a Ruby class, you don’t need to
resort to a hash table to map between lines (keys) and split lines (values).
Instead you employ a very common Ruby idiom, combining an instance variable
@values, with the ||=
operator. Instance variables are the perfect place to cache information such as
method return values.
Breaking All the Rules
Now your code is much easier to read. Using an object oriented instead of a
functional design turned out to be a good idea.

With your object oriented solution, you have broken some of the most important
rules of functional programming: First, you created hidden state, the @line instance variable, wrapping it up and hiding it
inside the Line class. The @values instance
variable holds even more state information. And second, the initialize and
values methods have side effects: They change the value of @line and @values. Finally,
all the other methods of Line are no longer pure functions! They return values
that depend on state located outside of each function: the @line variable. In fact, they can return different values
even though they take no arguments at all.
But I believe these are technicalities. You haven’t lost the benefits of
functional programming with this refactoring. While the methods of Line depend on external state (@line and @values), that state
isn’t located very far away. It’s still easy to predict, understand and test
what these small functions do. Also, while @line is
technically a mutable string that you change in your program, in practice it
isn’t. You set it once using initialize and then
never change it again. While you may update @values
each time values is called, it's just a performance
optimization. It doesn’t change the overall behavior of values.
You’ve broken the rules and rewritten your pure, functional program is a more
idiomatic, Ruby manner. However, you haven’t lost the spirit of functional
programming. Your code is just as easy to understand, maintain and test.
Creating an Object Pipeline
Wrapping up, you refactor your original program to use your new Line class like this:

Of course, there’s not much difference here. You simply added a line of code to
create new line objects, and then called its methods instead of your original
functions.
Finally, you decide to take one step further and refactor again by mapping the
array of text lines to an array of line objects:

Again, not much difference in the code. However, the way you think about your
program has changed dramatically. Now your code implements a pipeline of sorts,
passing data through a series of operations or transformations. You start with
an array of text lines from a file, convert them into an array of Ruby objects,
and finally process each object using your parse functions.
This pattern of passing data through a series of operations is common in
languages such as Haskell and Clojure. What’s interesting here is how Ruby
objects are the perfect target for these operations. You’ve used a Ruby class
to implement a functional programming pattern.
Update: [Oren Dobzinski](https://twitter.com/orend) suggested adding a
to_s method to
Line, which
would allow us to push the object pipeline idea even further. Thanks Oren! See
Dave Thomas's article [Telling, Asking, and the Power of
Jargon](http://pragdave.me/blog/2014/02/11/telling-asking-and-the-power-of-jargon/)
for more background on "Tell, Don't Ask."