Generational GC in Python and Ruby

Both the Ruby and Python garbage collectors
handle old and young objects differently.
Last week I wrote up the my first half of my notes from a presentation I did at RuPy called “Visualizing Garbage Collection in Ruby and Python.” I explained how standard Ruby (also known as Matz’s Ruby Interpreter or MRI) uses a garbage collection (GC) algorithm called mark and sweep, the same basic algorithm developed for the original version of Lisp in 1960. We also saw how Python uses a very different GC algorithm also invented 53 years ago called reference counting.
As it turns out, along with reference counting Python employs a second algorithm called generational garbage collection. This means Python’s garbage collector handles newly created objects differently than older ones. And starting with the upcoming version 2.1 release, MRI Ruby will also employ generational GC for the first time. (Two alternative implementations of Ruby, JRuby and Rubinius, have been using generational garbage collection for years. I’ll talk about how garbage collection works inside of JRuby and Rubinius next week at RubyConf.)
Of course, the phrase “handles new objects differently from older ones” is a bit of hand-waving. What exactly are new and old objects? Exactly how do Ruby and Python handle them differently? Today I’ll continue to describe how these two garbage collectors work and answer these questions. But before we get to generational GC, we first need to learn more about a serious theoretical problem with Python’s reference counting algorithm.
Update: If you speak Russian, there's a translation of this article by Vlad Brown on HTR.
Cyclic Data Structures and Reference Counting in Python
We saw last time that Python uses an integer value saved inside of each object, known as the reference count, to keep track of how many pointers reference that object. Whenever a variable or other object in your program starts to refer to an object, Python increments this counter; when your program stops using an object, Python decrements the counter. Once the reference count becomes zero, Python frees the object and reclaims its memory.
Since the 1960s, computer scientists have been aware of a theoretical problem with this algorithm: if one of your data structures refers to itself, if it is a cyclic data structure, some of the reference counts will never become zero. To better understand this problem let’s take an example. The code below shows the same Node class we used last week:

We have a constructor (these are called __init__ in Python) which saves a single attribute in an instance variable. Below the class definition we create two nodes, ABC and DEF, which I represent using the rectangles on the left. The reference count inside both of our nodes is initially one, since one pointer (n1 and n2, respectively) refers to each node.
Now let’s define two additional attributes in our nodes, next and prev:
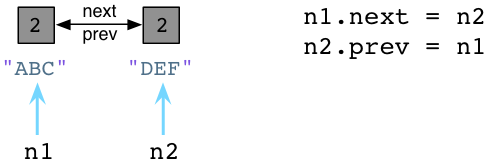
Unlike in Ruby, using Python you can define instance variables or object attributes on the fly like this. This seems like a bit of interesting magic missing from Ruby. (Disclaimer: I’m not a Python developer so I might have some of the nomenclature wrong here.) We set n1.next to reference n2, and n2.prev to point back to n1. Now our two nodes form a doubly linked list using a circular pattern of pointers. Also notice that the reference counts of both ABC and DEF have increased to two. There are two pointers referring to each node: n1 and n2 as before, and now next and prev as well.
Now let’s suppose our Python program stops using the nodes; we set both n1 and n2 to null. (In Python null is known as None.)

Now Python, as usual, decrements the reference count inside of each node down to 1.
Generation Zero in Python
Notice in the diagram just above we’ve ended up with an unusual situation: We have an “island” or a group of unused objects that refer to each other, but which have no external references. In other words, our program is no longer using either node object, therefore we expect Python’s garbage collector to be smart enough to free both objects and reclaim their memory for other purposes. But this doesn’t happen because both reference counts are one and not zero. Python’s reference counting algorithm can’t handle objects that refer to each other!
Of course, this is a contrived example, but your own programs might contain circular references like this in subtle ways that you may not be aware of. In fact, as your Python program runs over time it will build up a certain amount of “floating garbage,” unused objects that the Python collector is unable to process because the reference counts never reach zero.
This is where Python’s generational algorithm comes in! Just as Ruby keeps track of unused, free objects using a linked list (the free list), Python uses a different linked list to keep track of active objects. Instead of calling this the “active list,” Python’s internal C code refers to it as Generation Zero. Each time you create an object or some other value in your program, Python adds it to the Generation Zero linked list:
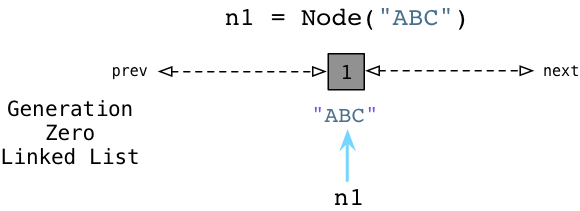
Above you can see when we create the ABC node, Python adds it to Generation Zero. Note that this isn’t an actual list that you see and access in your program; this linked list is entirely internal to the Python runtime.
Similarly, when we create the DEF node, Python adds it to the same linked list:
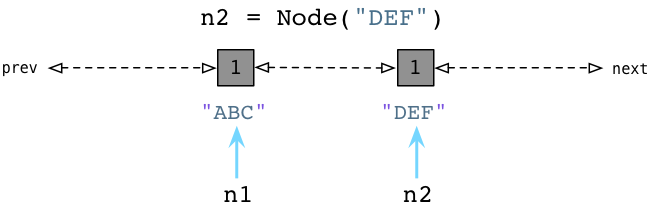
Now Generation Zero contains two node objects. (It will also contain every other value our Python code creates, and many internal values used by Python itself.)
Detecting Cyclic References
Later Python loops through the objects in the Generation Zero list and checks which other objects each object in the list refers to, decrementing reference counts as it goes. In this way, Python accounts for internal references from one object to another that prevented Python from freeing the objects earlier.
To make this a bit easier to understand, let’s take an example:
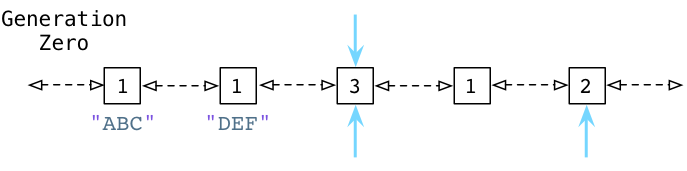
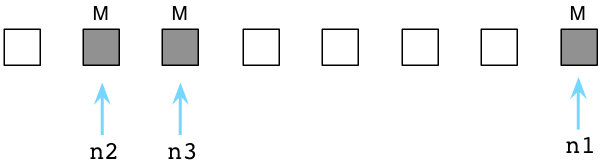
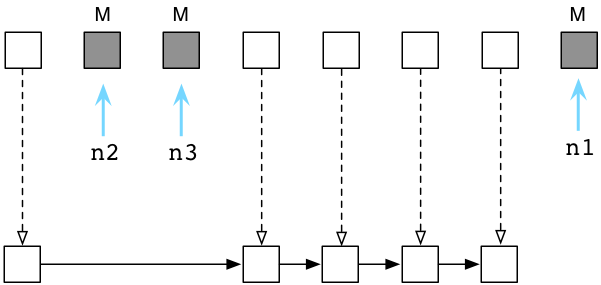
Above you can see the ABC and DEF nodes contain a reference count of 1. Three other objects are in the Generation Zero linked list also. The blue arrows indicate some of the objects are referred to by other objects that are located elsewhere - references from outside of Generation Zero. (As we’ll see in a moment, Python also uses two other lists called Generation One and Generation Two.) These objects have higher reference counts because of the other pointers referring to them.
Below you can see what happens after Python’s garbage collector processes Generation Zero.
By identifying internal references, Python is able to reduce the reference count of many of the Generation Zero objects. Above in the top row you can see that ABC and DEF now have a reference count of zero. This means the collector will free them and reclaim their memory. The remaining live objects are then moved to a new linked list: Generation One.
In a way, Python’s GC algorithm resembles the mark and sweep algorithm Ruby uses. Periodically it traces references from one object to another to determine which objects remain live, active objects our program is still using - just like Ruby’s marking process.
Garbage Collection Thresholds in Python
When does Python perform this marking process? As your Python program runs, the interpreter keeps track of how many new objects it allocates, and how many objects it frees because of zero reference counts. Theoretically, these two values should remain the same: every new object your program creates should eventually be freed.
Of course, this isn’t the case. Because of circular references, and because your program uses some objects longer than others, the difference between the allocation count and the release count slowly grows. Once this delta value reaches a certain threshold, Python’s collector is triggered and processes the Generation Zero list using the subtract algorithm above, releasing the “floating garbage” and moving the surviving objects to Generation One.
Over time, objects that your Python program continues to use for a long time are migrated from the Generation Zero list to Generation One. Python processes the objects on the Generation One list in a similar way, after the allocation-release count delta value reaches an even higher threshold value. Python moves the remaining, active objects over to the Generation Two list.
In this way, the objects that your Python program uses for long periods of time, that your code keeps active references to, move from Generation Zero to One to Two. Using different threshold values, Python processes these objects at different intervals. Python processes objects in Generation Zero most frequently, Generation One less frequently, and Generation Two even less often.
The Weak Generational Hypothesis
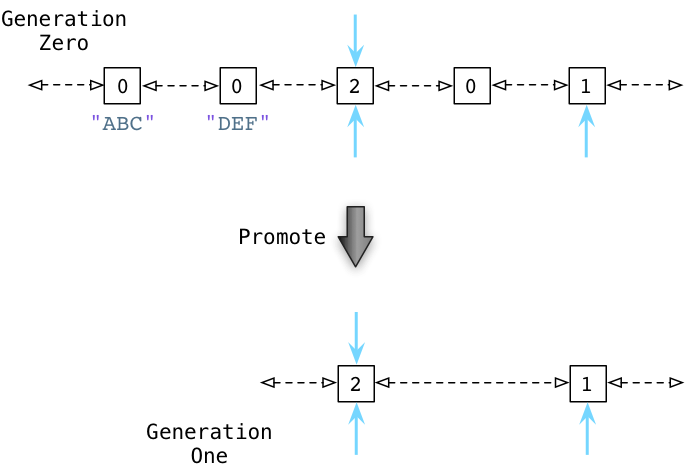
This behavior is the crux of the generational garbage collection algorithm: the collector processes new objects more frequently than old objects. A new, or young object is one that your program has just created, while an old or mature object is one that has remained active for some period of time. Python promotes an object when it moves it from Generation Zero to One, or from One to Two.
Why do this? The fundamental idea behind this algorithm is known as the weak generational hypothesis. The hypothesis actually consists of two ideas: that most new objects die young, while older objects are likely to remain active for a long time.
Suppose I create a new object using Python or Ruby:
According to the hypothesis, my code is likely to use the new ABC node only for a short time. The object is probably just an intermediate value used inside of one method and will become garbage as soon as the method returns. Most new objects will become garbage quickly in this way. Occasionally, however, my program creates a few objects that remain important for a longer time - such as session variables or configuration values in a web application.
By processing the new objects in Generation Zero more frequently, Python’s garbage collector spends most of its time where it will benefit the most: it processes the new objects which will quickly and frequently become garbage. Only rarely, when the allocation threshold value increases, does Python’s collector process the older objects.
Back to the Free List in Ruby
The upcoming release of Ruby, version 2.1, now uses a generational garbage collector algorithm for the first time! (Remember, other implementations of Ruby, such as JRuby and Rubinius, have been using this idea for years.) Let’s return to the free list diagrams from my last post to understand how this works.
Recall that when the free list is used up, Ruby marks the objects your program is still using:
In this diagram, we see there are three active objects because the pointers n1, n2 and n3 still refer to them. The remaining objects, the white squares, are garbage. (Of course, the free list will actually contain thousands of objects that refer to each other in complex patterns. My simple diagrams help me communicate the basic ideas behind Ruby’s GC algorithm without getting bogged down in the details.)
Also recall that Ruby moves the garbage objects back onto the free list, because now they can be recycled and reused by your program when it allocates new objects:
Generational GC in Ruby 2.1
Starting with Ruby 2.1, the GC code takes an additional step: it promotes the remaining active objects to the mature generation. (The MRI C source code actually uses the word old and not mature.) This diagram shows a conceptual view of the two Ruby 2.1 object generations:
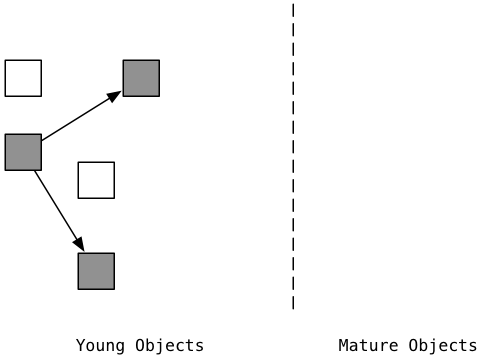
On the left is a different view of the free list. We see the garbage objects in white, and the remaining live, active objects in gray. The gray objects were just marked.
Once the mark and sweep process is finished, Ruby 2.1 will consider the remaining marked objects to be mature:
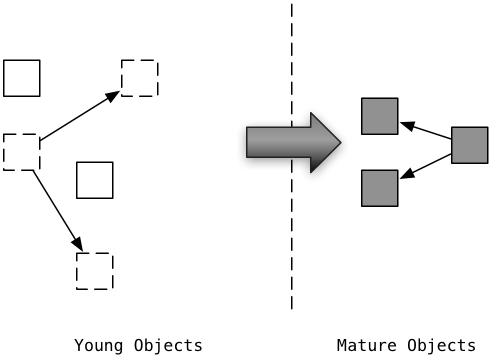
Instead of using three generations like Python, Ruby 2.1’s garbage collector uses just two. On the left are new objects in the young generation, and on the right are old objects in the mature generation. Once Ruby 2.1 has marked an object once, it considers it to be mature. Ruby bets the object has remained active for a long enough time that it will not become garbage quickly.
Important note: Ruby 2.1 doesn’t actually copy objects around in memory. These generations don’t consist of different areas of physical memory. (Some GC algorithms used by other languages and other Ruby implementations, known as copying garbage collectors, do actually copy objects when they are promoted.) Instead, Ruby 2.1 uses code internally that doesn’t include previously marked objects in the mark and sweep process again. Once an object has been marked once it won’t be included in the next mark and sweep process.
Now suppose your Ruby program continues to run, creating more new, young objects. These appear in the young generation again, on the left:
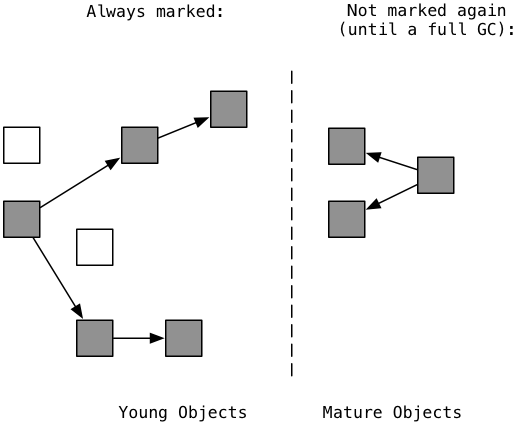
Just like Python, Ruby’s collector focuses its efforts on the young generation. It only includes the new, young objects created since the last GC process occurred in the mark and sweep algorithm. This is because many new objects are likely to be garbage already (the white boxes on the left). Ruby doesn’t re-mark the mature objects on the right. Because they already survived one GC process, they are likely to remain active and not become garbage for a longer time. By only marking young objects, Ruby’s GC code runs much faster. It just skips over the mature objects entirely, reducing the amount of time your program is waiting for garbage collection to finish.
Occasionally Ruby runs a “full collection,” re-marking and re-sweeping the mature objects as well. Ruby decides when to run a full collection by monitoring the number of mature objects. When the number of mature objects has doubled since the last full collection, Ruby clears the marks and considers all the objects to be young again.
Write Barriers
One important challenge to this algorithm is worth further explanation. Suppose your code creates a new, young object and adds it as a child of an existing, mature object. For example, this would happen if you added a new value to an array that had existed for a long time.
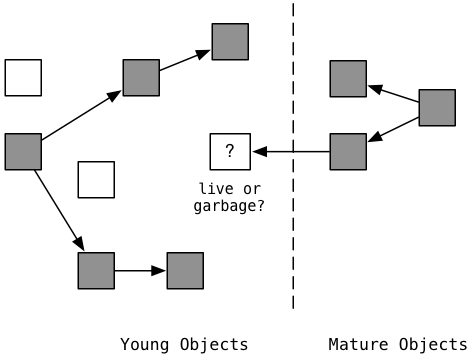
Here again on the left we see new, young objects and mature objects on the right. On the left side the marking process has identified that 5 new objects are still active (gray), while two new objects are garbage (white). But what about the new, young object in the center? This is the one shown in white with a question mark. Is this new object garbage or active?
It’s active, of course, because there’s a reference to it from a mature object on the right. But remember Ruby 2.1 doesn’t include mature objects in mark and sweep (until a full collection occurs). This means the new object will be incorrectly considered garbage and released, causing your program to lose data!
Ruby 2.1 overcomes this challenge by monitoring the mature objects to see if your program adds a reference from them to a new, young object. Ruby 2.1 uses an old GC technique called write barriers to monitor changes to mature objects - whenever you add a reference from one object to another (whenever you write to or modify an object), a write barrier is triggered. The barriers check whether the source object is mature, and if so adds the mature object to a special list. Later Ruby 2.1 includes these just these modified mature objects in the next mark and sweep process, preventing active, young objects from being incorrectly considered garbage.
Ruby 2.1’s actual implementation of write barriers is quite complex, primarily because existing C extensions don’t contain them. Koichi Sasada and the Ruby core team used a number of clever solutions to overcome this challenge as well. To learn more about these technical details, watch Koichi’s fascinating presentation from EuRuKo 2013.
Standing on the Shoulders of Giants
At first glance, Ruby and Python seem to implement garbage collection very differently. Ruby uses John McCarthy’s original mark and sweep algorithm, while Python uses reference counting. But when we look more closely, we see that Python uses bits of the mark and sweep idea to handle cyclic references, and that both Ruby and Python use generational garbage collection in similar ways. Python uses three separate generations, while Ruby 2.1 uses two.
This similarity should not be a surprise. Both languages are using computer science research that was done decades ago - before either Ruby or Python were even invented. I find it fascinating that when you look “under the hood” at different programming languages, you often find the same fundamental ideas and algorithms are used by all of them. Modern programming languages owe a great deal to the ground breaking computer science research that John McCarthy and his contemporaries did back in the 1960s and 1970s.


