Ruby MRI Source Code Idioms #2: C That Resembles Ruby
 |
| Reading Ruby’s C source code can be as easy as reading your own Ruby code |
Last week I discussed how Ruby’s C source code uses macros to access data values. I explained that this “MRI Idiom” can make Ruby’s source a bit confusing for C programmers to read, but at the same time can make it easier to follow for Ruby developers who aren’t experienced with C. Today I want to continue this series and talk about another MRI idiom: how Ruby’s C source code frequently resembles Ruby code.
Sounds hard to believe, doesn’t it? At first glance MRI’s C source code looks nothing like Ruby. For example, take a look at the implementation of Array#collect:

This is typical C code: verbose, confusing and hard to understand. Ruby is supposed to be elegant and concise! However, I honestly believe this C code does resemble Ruby, and in fact implements Array#collect just the way you would if you were to implement this in Ruby.
Of course, we don’t need to imagine how we would implement this in Ruby - there already is a Ruby version of Array#collect (actually Enumerable#collect) in Rubinius:
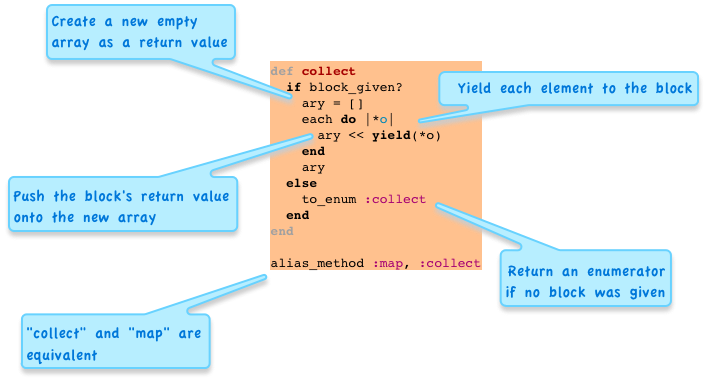
Now let’s take a second look at MRI’s C implementation - if you have a vivid imagination you can see how the MRI C code corresponds to the Ruby used by Rubinius:

My point is that by learning a few of MRI’s idioms and coding patterns, you can begin to read Ruby’s C source code just as easily as you can read Rubinius’s Ruby implementation.
Why would you want to do this? Why not refer to the Rubinius source code base whenever you have a question about how something works? This is actually a great idea; Rubinius is a particularly beautiful implementation of Ruby, and reading its code can give you a lot of insight into what’s going on inside of Ruby. However, most of us don’t run Rubinius in production. If you really need to know how something works at a detailed level... why it is slow, why it is fast, how or when does it allocate memory, etc., then there is no alternative but to read the C code you are actually running in production.
Today I’m going to examine how the C constructs in rb_ary_collect work in detail, and show how we can replace them - in our minds at least - with the corresponding Ruby code. By investing a bit of time to learn just a few of MRI’s coding patterns you’ll be able to understand not only rb_ary_collect, but many of the built in methods from classes such as String, Array, or File that you use everyday in your code. Understanding MRI’s idioms will allow you to follow much of Ruby’s internal source code without being an expert C developer.
First, a review of what Array#collect does
Let’s start by reviewing how the collect method works in Ruby. Here’s the example from the Ruby documentation:

Most of the time we use collect to iterate over an array (or some other Enumerable) and call a block for each element. Later collect pushes the return values from each call to the block into a single new array, and returns it.
However, if you call collect without a block it returns an enumerator object you can use later:
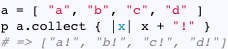
Now let’s see how Ruby implements Array#collect internally. I’ll do this by replacing bits of the confusing C code with Ruby, step by step. As you’ll see, this isn’t that hard to do!
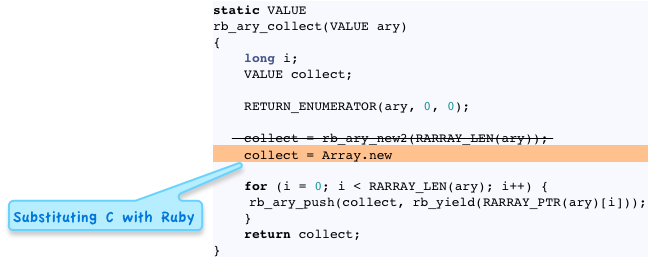
rb_ary_new2 = Array.new
This oddly named C function is actually quite simple: it just creates a new Array with a length of zero, and the given “capacity.” As I explained last week, internally Ruby saves a “capacity” value inside of each array, in the RArray structure, which keeps track of the size of the memory actually allocated for the array. The confusing part of this function is the name: rb_ary_new2 doesn’t create two arrays, or call the “new2” method on the Array class. It’s simply equivalent to calling Array.new in Ruby. MRI uses the number “2” on the function name to distinguish it from other functions that also create arrays in slightly different ways, for example without the internal capacity setting. Let’s take a look what rb_ary_new2 does:

You can see it just calls ary_new with the given capacity value, and by passing in rb_cArray indicates we want to create a new instance of the Array class (sometimes Ruby uses the RArray struct for instances of other classes):

I won’t explain this in detail, but you can see at the top Ruby checks the capacity parameter is valid, and gets a new RArray struct using the ary_alloc function. Finally it sets up this new RArray if necessary. I’ll explain the details around RARRAY_EMBED_LEN_MAX in my next post.
Now let’s return to rb_ary_collect and substitute the Ruby Array.new call into our C code - just as a thought experiment, of course!
for-loop = Array#each
Next, let’s look at how Ruby internally iterates over the array’s elements:

Of course, in Ruby I would never use a for-loop like this; instead I would call Array.each and pass each element to a block. But remember in the C language there is no concept of blocks or enumerators. Instead, you have to code “closer to the metal” and explain to the C compiler exactly how it should iterate through the array. Here’s how this works: first the code above creates a loop and assigns the values 0, 1, 2… to the variable i. Next, Ruby accesses each value of the array using this syntax:

As I explained last week, the RARRAY_PTR returns a pointer to the array’s actual data, and [i] uses C’s array syntax to obtain the proper element of the array.
Now in our thought experiment if we substitute the for-loop with a call to Array#each, passing a block parameter we get:
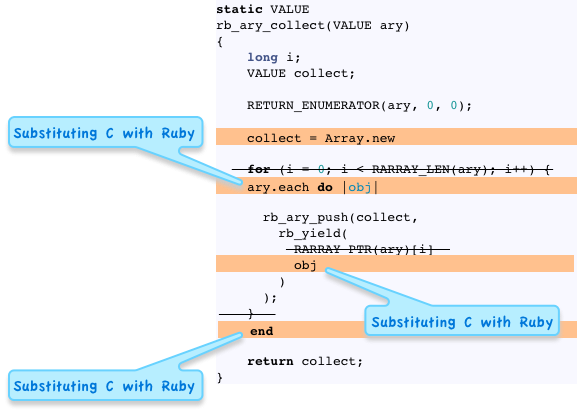
Now this C code is starting to make more sense!
rb_yield = yield
Now let’s take a look at what happens inside the loop. As you can see, Ruby takes each element of the array and passes it to a C function called rb_yield. As you might guess, this is Ruby’s internal implementation of the Ruby yield keyword. I don’t have time or space today to explain how rb_yield works in detail here - it calls into the internal guts of the YARV virtual machine that runs your Ruby program. For a good explanation of how YARV works and of what Ruby does internally when you call a block, check out chapters 2 and 5 from Ruby Under a Microscope, my eBook on Ruby internals.
Let’s continue the thought experiment and substitute rb_yield with a simple Ruby yield keyword:
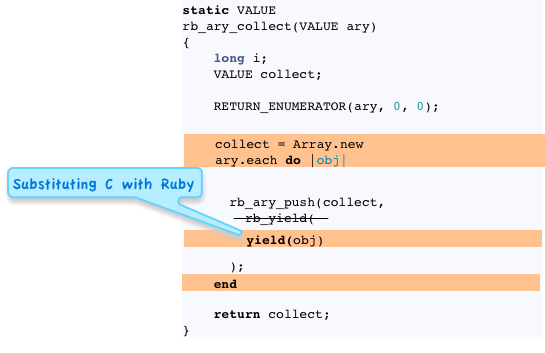
rb_ary_push = Array#<<
Next, let’s take a look at the rb_ary_push function call. As you might guess, this simply calls Array#<<. It adds a new value to the end of the array. Let’s take a quick look at the implementation of this, much farther above in the same array.c MRI source code file:

I won’t explain this code carefully, but in a nutshell Ruby uses another C function called rb_ary_push_1 as a optimization when you push a single new element. The related Array#push method can possibly take more than one parameter, so it’s handled slightly differently inside of MRI.
An interesting detail here how Ruby doubles the internal capacity of the array when there’s no room for another value, based on the “capacity” value. This is an optimization to avoid calling malloc to allocate memory over and over again as you push elements onto the array. Allocating (or reallocating) memory can often be an expensive operation.
Following the same pattern, I’ll substitute a call to Array#<< into my original C function - now the C code is looking more and more like the Rubinius implementation:

RETURN_ENUMERATOR = Kernel.to_enum
As you can see, there’s just one last bit of confusing C code left from the original version of rb_ary_collect - the RETURN_ENUMERATOR macro. Let’s take a look at how this macro is written, from include/ruby/intern.h:

Ah yes… typical C verbosity! We have a multiline macro with backslashes, and a needless do...while loop inserted around the actual macro to provide a safe scope for substitution. What in the world does this mean?
Don’t panic! This code isn’t that hard to understand if you take a moment to read it carefully; it essentially means: if a block was not given then call the rb_enumeratorize function, passing in the name of the current C function as a parameter. Then return the result as the return value for rb_ary_collect.
Ruby uses this RETURN_ENUMERATOR macro quite often while implementing methods related to enumeration, such as collect or each. You can find the rb_enumeratorize function in the enumerator.c MRI source code file, but I won’t explain it here. There’s some complex code that eventually does the same thing a call to Kernel.to_enum does - which is to return a new enumerator object that is initialized with the values in the current array.
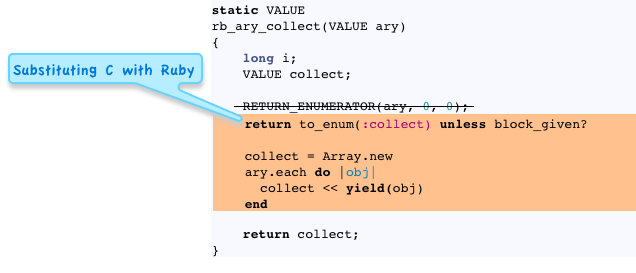
Replacing this macro with the equivalent call to Kernel.to_enum, I get:
Conclusion
Let’s take a step back and review what I’ve done in this odd thought experiment. Reading the original implementation of rb_ary_collect I recognized some idiomatic C patterns that I was familiar with. This allowed me - in my own head at least - to read the C source code the same way I would read a Ruby function. Notice how similar the code above is to Rubinius’s implementation:

My point today is that by learning a few of the C coding patterns the Ruby core team uses, you can start to read Ruby’s source code just as easily as you can read your own Ruby code. This is especially true for Ruby’s implementation of built-in methods like Array#collect.


