How Ruby Borrowed a Decades Old Idea From Lisp
This is the last of a series of free excerpts from an eBook I’m writing called Ruby Under a Microscope. I plan to finish the book and make it available for purchase and download from this web site before RubyConf 2012 on Nov. 1. You can still sign up here, if you haven’t already, to receive an email when the book is finished. I plan send that one, single email message out to everyone before November!
 |
| The IBM 704, above, was the first computer to run Lisp in the early 1960s. |
Blocks are one of the most commonly used and powerful features of Ruby. As you probably know, they allow you to pass a code snippet to iterators such as each, detect or inject. You can also write your own functions that call blocks for other reasons using the yield keyword. Ruby code containing blocks is often more succinct, elegant and expressive than the equivalent code would appear in older languages such as C.
However, don’t jump to the conclusion that blocks are a new idea! In fact, blocks are not new to Ruby at all; the computer science concept behind blocks, called “closures,” was first invented by Peter J. Landin) in 1964, a few years after the original version of Lisp was created by John McCarthy in 1958. Closures were later adopted by Lisp - or more precisely a dialect of Lisp called Scheme, invented by Gerald Sussman and Guy Steele in 1975. Sussman and Steele’s use of closures in Scheme brought the idea to many programmers for the first time starting in the 1970s.
But what does “closure” actually mean? In other words, exactly what are Ruby blocks? Are they as simple as they appear? Are they just the snippet of Ruby code that appears between the do and end keywords? Or is there more to Ruby blocks than meets the eye? In this chapter I’ll review how Ruby implements blocks internally, and show how they meet the definition of “closure” used by Sussman and Steele back in 1975. I’ll also show how blocks, lambdas, procs and bindings are all different ways of looking at closures, and how these objects are related to Ruby’s metaprogramming API.
 |
| Sussman and Steele gave a useful definition of the term “closure” in this 1975 academic paper, one of the so-called “Lambda Papers.” |
What exactly is a block?
Internally Ruby represents each block using a C structure called rb_block_t:
One way to define what a block is would be to take a look at the values Ruby stores inside this structure. Just as we did in Chapter 3 with the RClass structure, let’s deduce what the contents of the rb_block_t structure must be based on what we know blocks can do in our Ruby code.
Starting with the most obvious attribute of blocks, we know each block must consist of a piece of Ruby code, or internally a set of compiled YARV byte code instructions. For example, if I call a method and pass a block as a parameter:
10.times do str = "The quick brown fox jumps over the lazy dog." puts str end
...it’s clear that when executing the 10.times call Ruby needs to know what code to iterate over. Therefore, we know the rb_block_t structure must contain a pointer to that code:
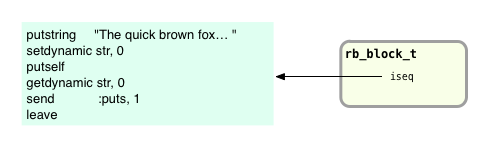
In this diagram you can see a value called iseq which is a pointer to the YARV instructions compiled from the Ruby code in my block.
Another obvious but often overlooked behavior of blocks is that they can access variables in the surrounding or parent Ruby scope. For example:
str = "The quick brown fox" 10.times do str2 = "jumps over the lazy dog." puts "#{str} #{str2}" end
Here the puts function call refers equally well to the str2 variable located inside the block and the str variable from the surrounding code. We often take this for granted - obviously blocks can access values from the code surrounding them. This ability is one of the things that makes blocks useful. But if you think about this for a moment, you’ll realize blocks have in some sense a dual personality. On the one hand they behave like separate functions: you can call them and pass them arguments just as you would with any function. But on the other hand they are part of the surrounding function or method. As I wrote the sample code above I didn’t think of the block as a separate function - I thought of the block’s code as just part of the simple, top level script that printed a string 10 times.
How does this work internally? Does Ruby internally implement blocks as separate functions? Or as part of the surrounding function? Let’s step through the example above, slowly, and see what happens inside of Ruby when you call a block.
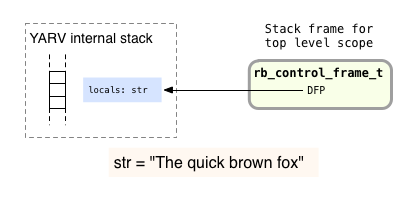
In this example when Ruby executes the first line of code, as I explained in Chapter 2, YARV will store the local variable str on it’s internal stack, and save it’s location in the DFP pointer located in the current rb_control_frame_t structure*. (*footnote: If the outer code was located inside a function or method then the DFP would point to the stack frame as shown, but if the outer code was located in the top level scope of your Ruby program, then Ruby would use dynamic access to save the variable in the TOPLEVEL_BINDING environment instead - more on this in section 4.3. Regardless the DFP will always indicate the location of the str variable.)
Next Ruby will come to the 10.times do call. Before executing the actual iteration - before calling the times method - Ruby will first create and initialize a new rb_block_t structure to represent the block. Ruby needs to create the block structure now, since the block is really just another argument to the times method:
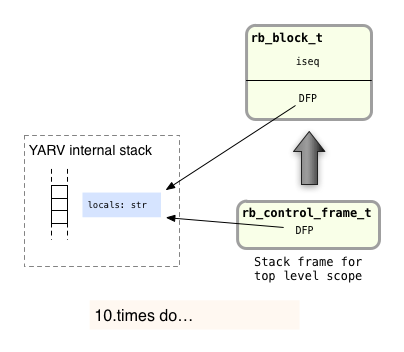
To do this, Ruby copies the current value of the DFP, the dynamic frame pointer, into the new block. In other words, Ruby saves away the location of the current stack frame in the new block.
Next Ruby will proceed to call the times method on the object 10, an instance of the Fixnum class. While doing this, YARV will create a new frame on its internal stack. Now we have two stack frames: on the top is the new stack frame for the Fixnum.times method, and below is the original stack frame used by the top level function:
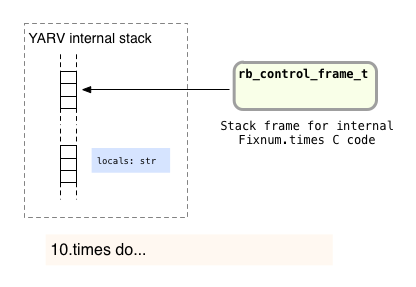
Ruby implements the times method internally using its own C code - it’s a built in method - but Ruby implements it the same way you probably would in Ruby. Ruby starts to iterate over the numbers 0, 1, 2, etc., up to 9, and calls yield once for each of these integers. Finally, the code that implements yield internally actually calls the block each time through the loop, pushing a third* frame onto the top of the stack for the code inside the block to use: (*footnote: Ruby actually pushes an extra, internal stack frame whenever you call yield before actually calling the block, so strictly speaking there should be four stack frames in this diagram. I only show three for the sake of clarity.)
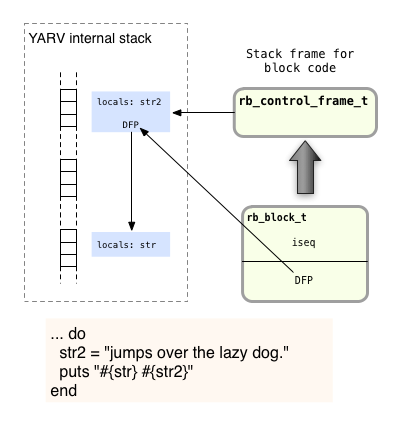
Here on the left we now have three stack frames:
- On the top is the new stack frame for the block, containing the str2 variable.
- In the middle is the stack frame used by the internal C code that implements the Fixnum.times method.
- And at the bottom is the original function’s stack frame, containing the str variable from the outer scope.
While creating the new stack frame at the top, Ruby’s internal yield code copies the DFP from the block into the new stack frame. Now the code inside the block can access both it’s own local variables, via the rb_control_frame structure as usual, and indirectly the variables from the parent scope, via the DFP pointer using dynamic variable access, as I explained in Chapter 2. Specifically this allows the puts statement to access the str variable from the parent scope.
To summarize, we have seen now that Ruby’s rb_block_t structure contains two important values: a pointer to a snippet of YARV code instructions, and a pointer to a location on YARV’s internal stack, the location that was at the top of the stack when the block was created:
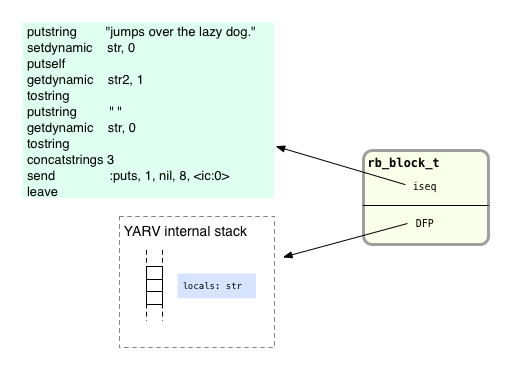
At first glance this seems like a very technical, unimportant detail. This is obviously a behavior we expect Ruby blocks to exhibit, and the DFP seems to be just another minor, uninteresting part of Ruby’s internal implementation of blocks.
Or is it? I believe the DFP is actually a profound, important part of Ruby internals. The DFP is the basis for Ruby’s implementation of “closures.” Here’s how Sussman and Steele defined the term “closure” in their 1975 paper Scheme: An Interpreter for Extended Lambda Calculus:
In order to solve this problem we introduce the notion of a closure [11, 14] which is a data structure containing a lambda expression, and an environment to be used when that lambda expression is applied to arguments.
Reading this again carefully, a closure is defined to be the combination of:
- A “lambda expression,” i.e. a function that takes a set of arguments, and
- An environment to be used when calling that lambda or function.
I’ll have more context and information about “lambda expressions” and how Ruby’s borrowed the lambda keyword from Lisp in section 4-2, but for now take another look at the internal rb_block_t structure:
Notice that this structure meets the definition of a closure Sussman and Steele wrote back in 1975:
- iseq is a pointer to a lambda expression, i.e. a function or code snippet, and
- DFP is a pointer to the environment to be used when calling that lambda or function, i.e. a pointer to the surrounding stack frame.
Following this train of thought, we can see that blocks are Ruby’s implementation of closures. Ironically blocks, one of the features that in my opinion makes Ruby so elegant and natural to read - so modern and innovative - is based on research and work done at least 20 years before Ruby was ever invented!
In Ruby 1.9 and later you can find the actual definition of the rb_block_t structure in the vm_core.h file. Here it is:
typedef struct rb_block_struct { VALUE self; /* share with method frame if it's only block */ VALUE *lfp; /* share with method frame if it's only block */ VALUE *dfp; /* share with method frame if it's only block */ rb_iseq_t *iseq; VALUE proc; } rb_block_t;
You can see the iseq and DFP values I described above, along with a few other values:
- self: As we’ll see in the next sections when I cover lambdas, procs and bindings, the value the self pointer had when the block was first referred to is also an important part of the closure’s environment. Ruby executes block code inside the same object context the code outside the block had.
- lfp: It turns out blocks also contain a local frame pointer, along with the dynamic frame pointer. However, Ruby doesn’t use local variable access inside of blocks; it doesn’t use the set/getlocal YARV instructions inside of blocks. Instead, Ruby uses this LFP for internal, technical reasons and not to access local variables.
- proc: Finally, Ruby uses this value when it creates a proc object from a block. As we’ll see in the next section, procs and blocks are closely related.
Right above the definition of rb_block_t in vm_core.h you’ll see the rb_control_frame_t structure defined:
typedef struct { VALUE *pc; /* cfp[0] */ VALUE *sp; /* cfp[1] */ VALUE *bp; /* cfp[2] */ rb_iseq_t *iseq; /* cfp[3] */ VALUE flag; /* cfp[4] */ VALUE self; /* cfp[5] / block[0] */ VALUE *lfp; /* cfp[6] / block[1] */ VALUE *dfp; /* cfp[7] / block[2] */ rb_iseq_t *block_iseq; /* cfp[8] / block[3] */ VALUE proc; /* cfp[9] / block[4] */ const rb_method_entry_t *me;/* cfp[10] */ } rb_control_frame_t;
Notice that this C structure also contains all of the same values the rb_block_t structure did: everything from self down to proc. The fact these two structures share the same values is actually one of the interesting, but confusing, optimizations Ruby uses internally to speed things up a bit. Whenever you refer to a block for the first time by passing it into a method call, as I explained above Ruby creates a new rb_block_t structure and copies values such as the LFP from the current rb_control_frame_t structure into it. However, by making the members of these two structures similar – rb_block_t is a subset of rb_control_frame_t – Ruby is able to avoid creating a new rb_block_t structure and instead sets the pointer to the new block to refer to the common portion of the rb_control_frame_t structure. In other words, instead of allocating new memory to hold a new rb_block_t structure, Ruby simple passes around a pointer to the middle of the rb_control_frame_t structure. This is very confusing, but does avoid unnecessary calls to malloc, and speeds up the process of creating blocks.
Experiment 4-1: Which is faster: a while-loop or passing a block to each?
… read it in the finished eBook.
Lambdas and Procs: treating code as a first class citizen
… read it in the finished eBook.
Experiment 4-2: Lambda/Proc performance - how long does it take Ruby to copy a stack frame to the heap?
… read it in the finished eBook.
Bindings: A closure environment without a function
… read it in the finished eBook.
Experiment 4-3: Exploring the TOPLEVEL_BINDING object.
… read it in the finished eBook.
Closures in JRuby
… read it in the finished eBook.
Closures in Rubinius
… read it in the finished eBook.


