Pointers in C and x86 Assembly Language

16GB of DDR random access memory
my son used in his new gaming PC
Recently I’ve been trying to learn how to read x86 assembly language. In my last post, I explored basic x86 syntax in a very simple program that used a few registers. But in that post I didn’t cover how instructions refer to values located in memory and not in a register. To be useful at all, x86 code must load data from memory into a register, and eventually save data from a register back into memory.
Assembly language instructions access values in memory by considering a register’s contents to be a memory address, and then dereferencing it the same way you would use a pointer in a C program. In fact, to me C and assembly language seem very similar in this way, which I suspect is not a coincidence.
Today I’ll read and try to understand a very simple x86 assembly language program that reads from and writes to memory. To make the x86 instructions a bit easier to follow, I’ll first rewrite them using C pointer syntax. If you’re an experienced C programmer, this will make the x86 code easy to read. Or if you’re not familiar with C, this is your chance to learn both C and x86 pointer syntax at the same time.
Writing A Program That Accesses Memory
But first, we need an example program that accesses memory. Where can I find one? Do I need to find some low level code from a device driver or operating system kernel? No, of course not! Every program you or I have ever written accesses memory. All I need to do is translate one of them into x86 assembly language.
I’ll use my Ruby example from last time, but with a new line of code that saves the constant value 42 into a local variable. After I compile it I’ll able able to look for the number 42 in the assembly language code:
def add_forty_two(n) a = 42 n+a end
Once again I’ll use Crystal to compile my Ruby code:
crystal build add_forty_two.rb --emit asm
Searching through the generated add_forty_two.s file, I find the
add\_forty\_two function, clean it up and paste its assembly language
instructions back into my Ruby function:
def add_forty_two(n) pushq %rbp movq %rsp, %rbp movl %edi, -8(%rbp) movl $42, -4(%rbp) movl -8(%rbp), %eax addl -4(%rbp), %eax popq %rbp retq end
Assembly Language: The Script Your Computer Follows
This code is quite literally the script my computer follows: What happens when
I call add_forty_two? How does my computer know what to do? How does it add 42
to the given argument? It follows the script.

trying to read an old Shakespearean manuscript
The problem is this script contains Old English words I don’t understand - and the words I do know are spelled differently. I can almost understand what this line of code means:
movl $42, -4(%rbp)
…but not quite. I can guess by reading my original Ruby code it’s probably
saving 42 in the local variable a. In my last post I learned that the “l”
suffix in movl means the instruction will move a long, or 32 bit value, from
one place to another. I also learned last time that the “$” prefix means the
number 42 is a constant.
But where is a located? And what does -4(%rbp) mean? The surrounding
instructions are worse; they use similar syntax but there are no clues as to
what they are doing. Like a frustrated high school student trying to read The
Tempest, I’m at a loss.
I need some cliff notes. I need to see this assembly language script translated into standard, modern English, a language I understand.
play. Equally confusing but somewhat easier to read.
Transcribing x86 Assembly Language into C
To illustrate what I mean, I’ll rewrite each x86 instruction with the equivalent C syntax:
If you’re an experienced C programmer, the pseudocode on the right side should be somewhat more readable. You can see how the x86 instructions access memory by interpreting register values as memory addresses, and how instructions can also pre-decrement or post-increment these addresses. We’ve translated something completely unfamiliar into a format that is somewhat easier to follow.
If you’re not familiar with C, then skip down to the next section, where I’ll explain what three of these instructions do. You’ll learn what the x86 and C notation means, how they are different and how they are similar.
C: A Mix of High And Low Level Notation
But while my C pseudocode is syntactically correct, it makes no sense. Negative array indices are normally invalid in C, and, of course, a C program would never directly reference registers on the CPU directly like this to begin with.
In fact, a proper C program to add 42 would resemble the Ruby code I started with above:
#include <stdio.h> unsigned int add_forty_two(n) { unsigned int a = 42; return a+n; } printf("50 + 42 is %d", add_forty_two(50));
My point today is that C mixes high and low level language notation. The underlying features and capabilities of my x86 microprocessor leak through into C programming syntax. Writing in C, I can create functions, variables and return values like a high level language, but I can also drop down to the level my microprocessor operates at, accessing memory directly using pointers.
And knowing how to use C pointers, I’m one step closer to understanding x86 assembly language. As we’ll see next, there are a few important differences between C and x86 notation which I need to understand carefully. But these are superficial. It turns out that simply by learning C I’ve also learned a lot about what my computer’s microprocessor is capable of.
In a future article I’ll try to figure out why the x86 instructions above do what they do - how my compiler assigns local variables to locations on the stack, and what the stack is. But for today, let’s focus on the meaning of the x86 and C pointer notation.
A Backwards, Inside Out Array
Let’s start with the move instruction that copies 42 into a certain memory address. Here’s the C translation:
rbp[-1] = 42;
This line of code looks simple enough, but actually there are a couple of very
odd things about it. First, I wrote the C array rbp using the name of a
register in my microprocessor. That is, I’m treating the rbp register as if it
were a series of values, an array, and not a single value.
Any C programmers reading along might not be surprised by this: In C an array is really just a pointer to a block of memory and not a collection of objects or elements like it would be in Python, Ruby or some other high level language. A recent blog article featured on Hacker News discusses what arrays really are in C: A convenient untruth.
The pointer itself is a number indicating where the memory block is located: a memory address:

In x86 assembly language, the same move instruction appears this way:
movl $42, -4(%rbp)
To me, the assembly language syntax is inside out: Instead of writing the array name followed by the index in brackets, I write the index first, followed by the array name in parentheses:

The parentheses indicate the move instruction should consider the value in rbp
to be a memory address, that it should move the value 42 to the memory address
referenced by rbp (or actually to the memory address four bytes before the
value of rbp) and not into rbp itself.

As you can see, the other odd thing about this array is that it uses a negative
index. The movl instruction copied 42 to a memory address that appeared before
the start of the array - this array is not only inside-out, it’s backwards!

In a C program, this would be a recipe for disaster. C programmers normally allocate memory for an array, and then access its elements using a positive (or zero) index value. Writing to a memory location using a negative index would overwrite memory located outside of the array, potentially causing a segmentation fault to occur immediately, or more likely causing my code to crash or misbehave later when it accessed this overwritten memory value.
x86 Array Indices
Reading the code above, you probably also noticed I wrote the C array using an index of -1, while the original x86 move instruction used -4. Why are these different? Why did I change the index values when I transcribed the assembly language into C?
The reason is that x86 assembly language instructions always use byte counts, while C arrays use an element count index instead. To understand what I mean, let’s write a C declaration for this imaginary array before using it:
unsigned int rbp[100]; rbp[2] = 42;
Because C is a statically typed language, I have to declare the type of the
array elements when I declare the array. In this example, unsigned int is
equivalent to a 32-bit or 4 byte value, the same operand size used by the movl
instruction. So here I’ve declared rbp as an array of 100 ints, using a memory
segment containing a total of 4*100=400 bytes.
Now when I write rbp[2] in C I access the element at position 2, or the third
element:
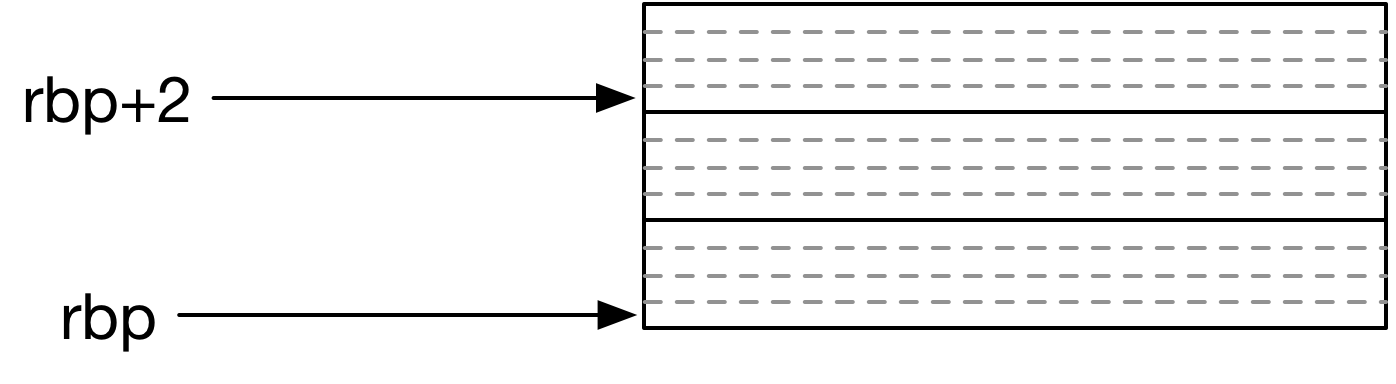
But notice that because each int element consists of 4 bytes, the memory
location of rbp+2 is actually 8 bytes larger than rbp. The index 2 is an
element count: (2 elements) * (4 bytes/element) = 8 bytes.
x86 assembly language, on the other hand, uses byte indexes. That means to
access the same element in this array, I would write 8(%rbp):

When you look at memory this way, from a detailed, physical point of view, the
x86 byte count index makes more sense. 8(%rbp) is the address rbp points to,
plus 8 bytes. But this isn’t very convenient: Think of all the code you’ve
written that uses arrays and their elements. Normally you don’t want to think
about how many bytes each element uses in memory, and exactly how many bytes
from the start of the array an element is located at. The C style of using an
element count index makes much more sense.
In the backwards array from my example program, the movl instruction was
written as:
movl $42, -4(%rbp)
This means “move the 4 byte long value 42 to a memory location 4 bytes before
the address found in the rbp register.”
But in C, I would write
rbp[-1] = 42;
This means “Set the -1st element of the array to 42” - much more straightforward (although still a bit weird).
Pushing a Value Onto The Stack
Next let’s take a look at the first x86 instruction in my program:
pushq %rbp
This instruction, pushq, pushes a new value onto the top of the stack. Think of
the stack as just a special array of values in memory. Reading the equivalent C
code makes this a bit easier to follow:
*--rsp = rbp;
Here I wrote the C assignment using explicit pointer syntax: The pointer is the
rsp or stack pointer register. The asterisk prefix is C notation for
dereferencing a pointer: *rsp refers to the value stored at the memory location
rsp points to, just as if I had written rsp[0]:

Ignoring the minus signs for a moment, the C code *rsp = rbp means: “copy the
value of rbp to the memory location whose address is contained in the rsp
register.”
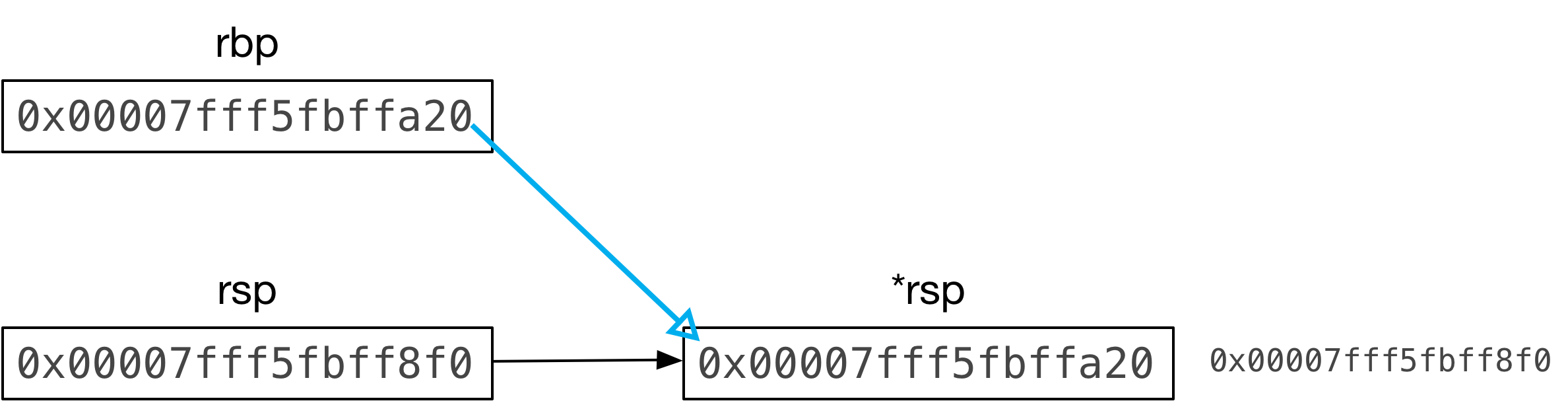
What about the minus signs? C programmers will know these indicate the pointer,
in this case rsp, should be decremented before its value is dereferenced. We
write the minus signs before the pointer because the decrement operation
happens before the pointer’s value is used. This is useful in this scenario
because rsp will continue to point to the top of the stack.
Imagine the rsp pointer starts at 0x00007fff5fbff8f8. This is the top of the
stack, initially:

Then we decrement rsp so it points to a new top of the stack. The stack grows
downward in x86 programs. Each time we push a value onto the stack we first
decrement the stack pointer:

And then the assignment writes the value of rbp to the top of the stack, using
rsp after it has been decremented:
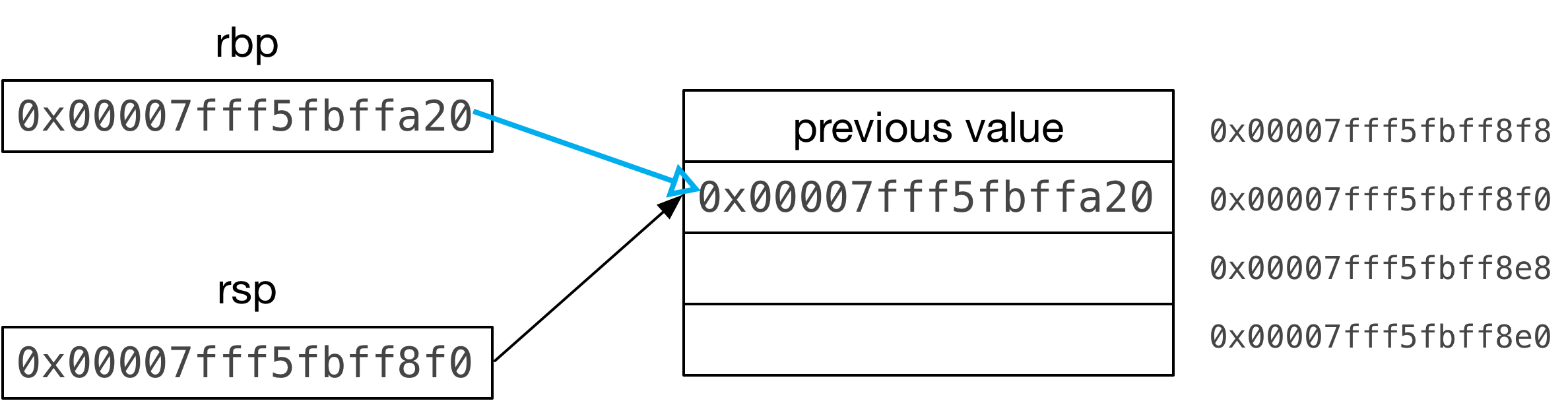
Notice another important detail here: The stack pointer is decremented by 8 bytes, not 4 bytes as above. This is because the values we push onto the stack in this example are pointers, or 8 byte values. We’ll see why in a moment.
What about the x86 notation? Pushing a value onto the stack is such a common
operation x86 microprocessors have a special instruction for it: push.
pushq %rbp
Just like with movl, the “q” suffix indicates how large the operand is, the
size of the value that push copies to the stack. In this case “q” indicates the
value is a 64 bit or 8 byte value. That’s why each value on the stack in the
diagram above takes 8 bytes. If my program had used the pushl instruction, then
it would have decremented the stack by only 4 bytes (a “long” instead of a
“quad” value).
This behavior of automatically adjusting the amount of decrement according to
the operand size is a convenient feature of x86 microprocessors. And it’s also
the origin of the C language -- and ++ operators. To see what I mean, take a
second look at the equivalent C assignment code:
*--rsp = rbp;
What does the -- pre-decrement operator subtract from the pointer rsp? The
answer is one element. If we imagine I declared rsp a pointer to an 8 byte long
value:
unsigned long *rsp; *--rsp = rbp;
…then decrementing rsp will subtract 8 bytes, enough for one unsigned long
value to fit. The -- operator uses the size of the pointer’s referenced type to
determine what value to subtract. And just like the pushq x86 instruction, the
C -- operator subtracts before the assignment occurs.
Why does the C -- operator function this way? Because the x86 assembly language
functions in the same way. Because my computer’s microprocessor works that way.
We’re seeing another example of how C’s behavior reflects the behavior and
capability of my computer’s microprocessor.
Popping a Value Off The Stack
Here’s the last instruction in my example program:
retq
This instruction, "return," means the microprocessor should return to the calling function and continue execution from there. How does it work? Once again, let’s refer to the equivalent C assignment function to learn more:
rip = *rsp++;
Here the C code copies the value from the memory location referenced by the rsp
pointer and saves it into the rip register.
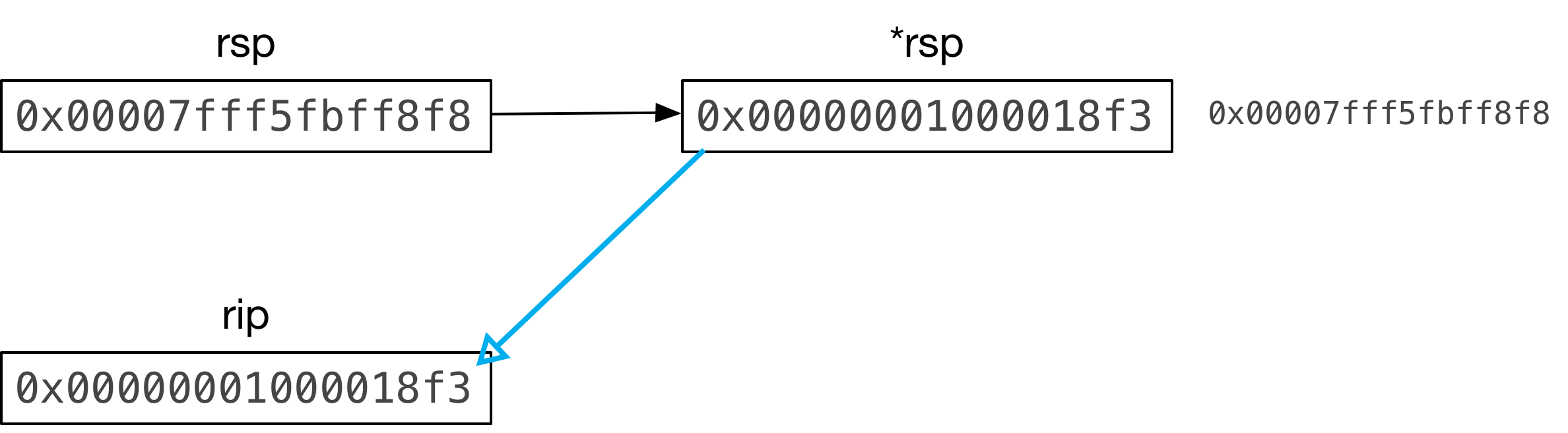
The rip register is known as the instruction pointer, which contains a very
special and important value: the memory address of the next instruction my
microprocessor should execute. This instruction copies an older value of rip
from the stack, and saves it into the rip register again.
Each time my program calls a function, the assembly language code saves the
current value of rip on the stack and then sets rip to a new value: the
location of the called function. When that function is finished, my program
then retrieves the old value of rip from the stack, continuing execute from
where it left off at the call site.
After copying the old value of rip from the stack, my program has to increment
the rsp pointer in order to keep the rsp register pointing to the top of the
stack. And in just the same way pushq did, retq uses the “q” suffix to
determine how many bytes to add to the stack pointer after the copy is
finished.

Now we know where the C ++ post-increment operator’s behavior comes from:
assembly language. Just as retq adds 8 bytes to rsp, the C expression *rsp++
adds the size of 1 element to rsp based on the type of the pointer’s referenced
type:
unsigned long *rsp; rip = *rsp++;
Next Time
When I have time I'd like to write one more post about x86 syntax. Now that I’ve learned what register prefixes and instruction suffixes mean in x86 code, and how to write instructions that use register values as memory addresses, I’m finally ready to read and understand a simple assembly language program. In my next point I’ll look at how my Crystal and C compilers assign memory addresses on the stack for local variables, and why they use a stack in the first place. Should be fun!


