Don’t Let Your Data Out of the Database

Don’t let your data escape from your database
and cause unintended performance mistakes.
Keep your data in the database, not for security reasons but to avoid performance mistakes. Often the best way to speed up your application is to let your database server do what it was designed to do: operate on data.
Most modern programming languages and frameworks hide databases behind an elegant, beautiful layer of abstraction. Developers today don’t need to write or even understand Structured Query Language (SQL), the native language of database servers. We view SQL as a low-level, technical relic of 1970s Computer Science, best left behind in academic journals and college classrooms.
However, not learning and thoroughly understanding SQL would be a tremendous mistake. In fact, many data related performance problems are a result of using a high level language, such as Ruby or Python, to work with data instead of SQL. Keep your data where it belongs… in the database. Use your database server to operate on your data in place, and then fetch the result your application actually needs.
Let me show you what I mean with a simple example.
Posts and Comments
Suppose I have data in a one-many relationship: one post has many comments. Using ActiveRecord, the popular Ruby ORM, I implement a one-many association by writing:
class Post < ActiveRecord::Base has_many :comments end class Comment < ActiveRecord::Base belongs_to :post end
Ruby’s powerful dynamic behavior allows me to query the comments for a given post in a very natural, human way:
post = Post.find(1) post.comments
But remember ActiveRecord isn’t a magic framework. It doesn’t have a secret connection to the tables in my database. It has to speak to the database server like everyone else, using the server’s language: SQL. Reading my log file, I can see how ActiveRecord translates post.comments into SQL:
select comments.* from comments where comments.post_id = 1
After executing this SQL statement, ActiveRecord converts the result set into an array of Ruby objects which I can then use in my code. For example, if I want the latest comment for a post I can write:
class Post def latest_comment comments.max {|a, b| a.updated_at <=> b.updated_at } end end
Here I ask Ruby to sort the comment objects and return the latest one, the comment with the maximum updated_at value. Now I can find the person who wrote the latest comment for a post just by writing:
post.latest_comment.author

Where Is My Data?
The problem with this approach is that it doesn’t scale. Suppose this post has hundreds or even thousands of comments; in this case, ActiveRecord will convert them all into Ruby objects just so I can iterate through them in the latest_comment method.
My mistake was to let my data out of the database. Instead, I should have asked the database do the work for me.
Let’s take a closer look at how latest_comment works:

On the right, I start with all of the comments in the database, tens of thousands of them let’s say. Next, I need to search for the comments associated with my post, filtering on the post_id column. This yields a subset, hundreds of comments for example. Finally, I sort these filtered comments and take the last one, yielding the latest one on the left.
The problem with my Ruby solution is that I perform the filtering in the database, but the sorting in Ruby. In between, the entire subset of comments for a post have to be transmitted from the database server to my Ruby application server:
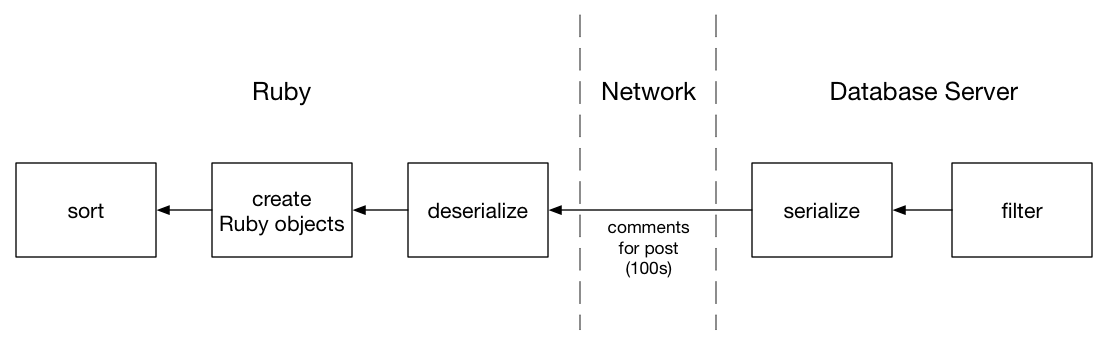
To transmit all of these records, the database needs to serialize them to some binary format, which my Ruby code (or my DB driver actually) later needs to unpack. Finally, ActiveRecord has to convert this binary data into Ruby objects.
This process takes time; in particular, creating hundreds or thousands of Ruby objects involves allocating a series of memory structures and placing them into a large array. Using a process called “garbage collection,” Ruby might even have to find and recycle older unused Ruby objects to hold the comments, which would take even more time.
Databases Are Faster Than You Are
The solution is obvious: perform the search inside the database and only return the latest comment. But how do I ask my database server to search for the latest comment? By using ActiveRecord methods such as where, order and first to describe what I want, instead of writing my own code in Ruby. This line will do the trick:
post.comments.order(updated_at: :desc).first
ActiveRecord translates this into SQL code as follows:
select comments.* from comments where comments.post_id = 1 order by comments.updated_at desc limit 1
This will run much faster than my previous solution, because my database only transmits one comment record over the network to my Ruby server: the latest one. And Ruby only creates one Ruby object, for the latest comment:
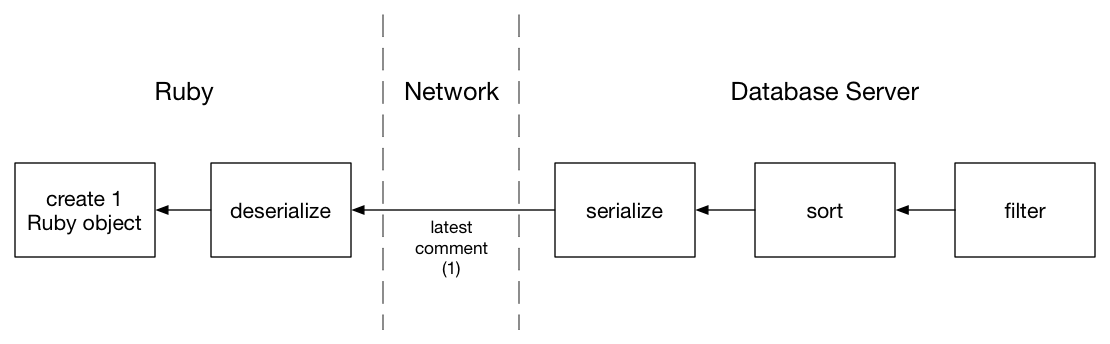
Now highly optimized C code, running on the same server that holds the comments table data, filters the comments by post, and sorts the matches by timestamp. This code has been used and tested by millions of developers around the world for years; don’t try to reinvent the wheel by rewriting the sort yourself using Ruby.
Caching the Latest Comment
Suppose in my user interface I always show the author of the latest comment next to each post. Now to display my page, I need to perform this comment search over and over again for every post. One way to avoid the comment query altogether would be to cache the latest comment’s author right inside the posts table. That way I’ll get the latest comment’s author automatically when I load the posts. No need for repeated searches, or any queries on the comments table at all!
In practice, if I’ve remembered to create indexes on the post_id and updated_at columns, the comment search SQL above will run very quickly, even if I execute it many times. I could even load the latest comments for all the posts using single SQL query, but for the sake of argument today, let’s explore a caching solution anyway.
Again ActiveRecord makes this easy. All I need to do is write a migration like this:
class AddLatestCommentAuthorToPosts < ActiveRecord::Migration def change add_column :posts, :latest_comment_author, :string end end
Now I just need to be sure to update the post each time a user writes a new comment:
post.update_attribute(:latest_comment_author, "user name")
Data Migration Using Ruby
Of course, I forgot something important. Using update_attribute I save the author for any new comments, but what about all of the existing comments? How do I set this column’s initial value for all the comments already in my database?
Simple enough: I just add a method to my migration that calls update_attribute. Here’s how to do it:
class AddLatestCommentAuthorToPosts < ActiveRecord::Migration def change add_column :posts, :latest_comment_author, :string populate_latest_comment_authors end def populate_latest_comment_authors Post.all.each do |post| latest_author = post.comments.order(updated_at: :desc).first.author post.update_attribute(:latest_comment_author, latest_author) end end end
Because you write migrations in Ruby, ActiveRecord makes it simple to perform complex transformations in a simple, elegant way. Using Ruby I get all the posts, iterate over each one, lookup the latest comment for that post, and update the latest comment author field.
But I’ve made the same performance mistake as before! Looking at my Rails log after running this migration, I find a series of repeated SQL statements:
SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 2]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 2 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.512160"]] SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 3]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 3 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.514676"]] SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 1]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 1 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.516071"]]
Again, I’ve let my data out of the database. By loading all of the posts using Post.all, and iterating over them using each, I’ve triggered this series of repeated SQL commands. Now I’m transmitting all of the post data, and then more data back and forth for each post between my database and my Ruby application:
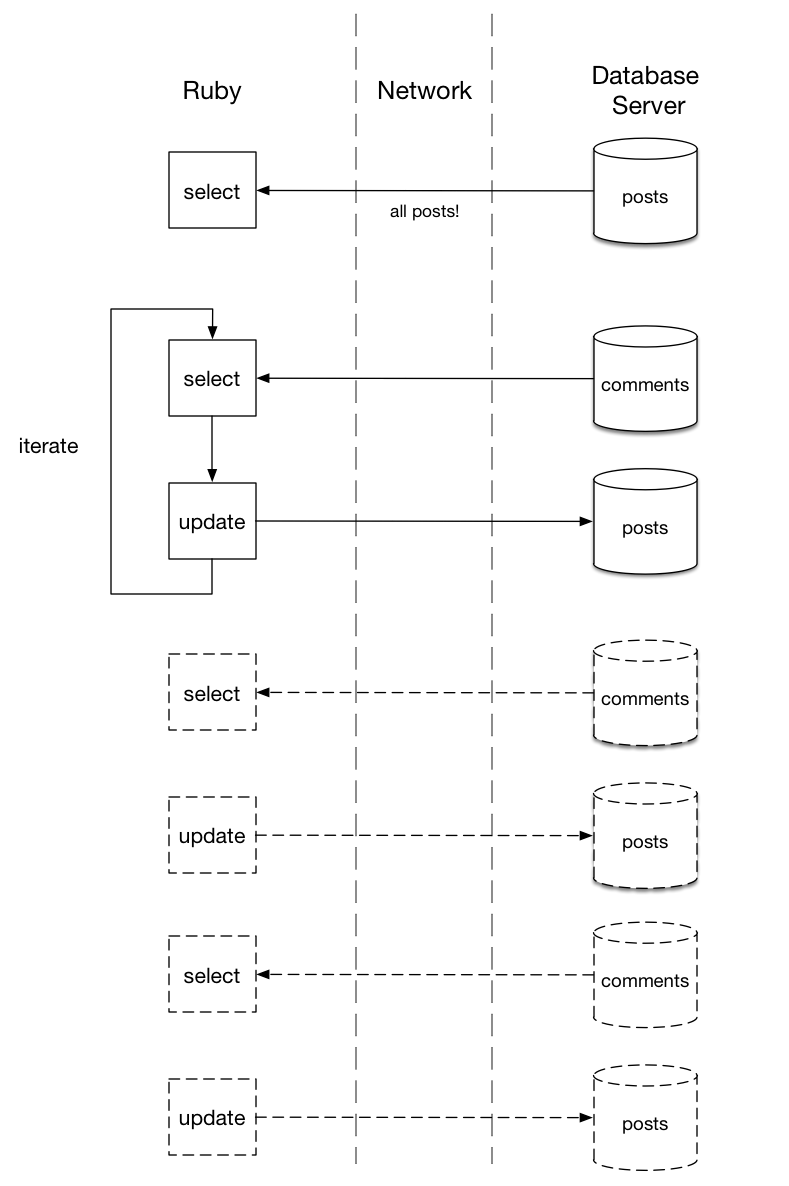
Just like my previous code, this migration will perform poorly. If I have just a few posts it probably doesn’t matter. But imagine if there are thousands or even 100,000s of post records: This migration might take minutes or even hours to complete! My database server and Ruby need to serialize, transmit and deserialize data for each one of these SQL commands.
There must be a better way.
Data Migration Using SQL
The solution is the same as before: Don’t let your data out of the database. Instead of writing Ruby code to update each post record, ask the database server to do it. My database server already has all my post data in an optimized format, likely loaded into memory. It can iterate over the posts and update them very quickly.

But how? How do I ask the database server to update all the posts? I need to speak the database’s language: SQL. By writing SQL directly, I can be sure the database is doing exactly what I want, that it’s using the most efficient algorithm possible. I can be sure my database and I understand each other.
Here’s one way to update all the posts using SQL:
update posts set latest_comment_author = ( select author from comments where comments.post_id = posts.id order by comments.updated_at desc limit 1 )
This tiny SQL program actually uses SQL commands similar to the what I found repeated in my log file. But there’s an important difference: This SQL code doesn’t refer to hard coded post id values, such as 1 or 2. Here I’ve updated all of the posts with a single command!
How does this work? Let’s take a look:
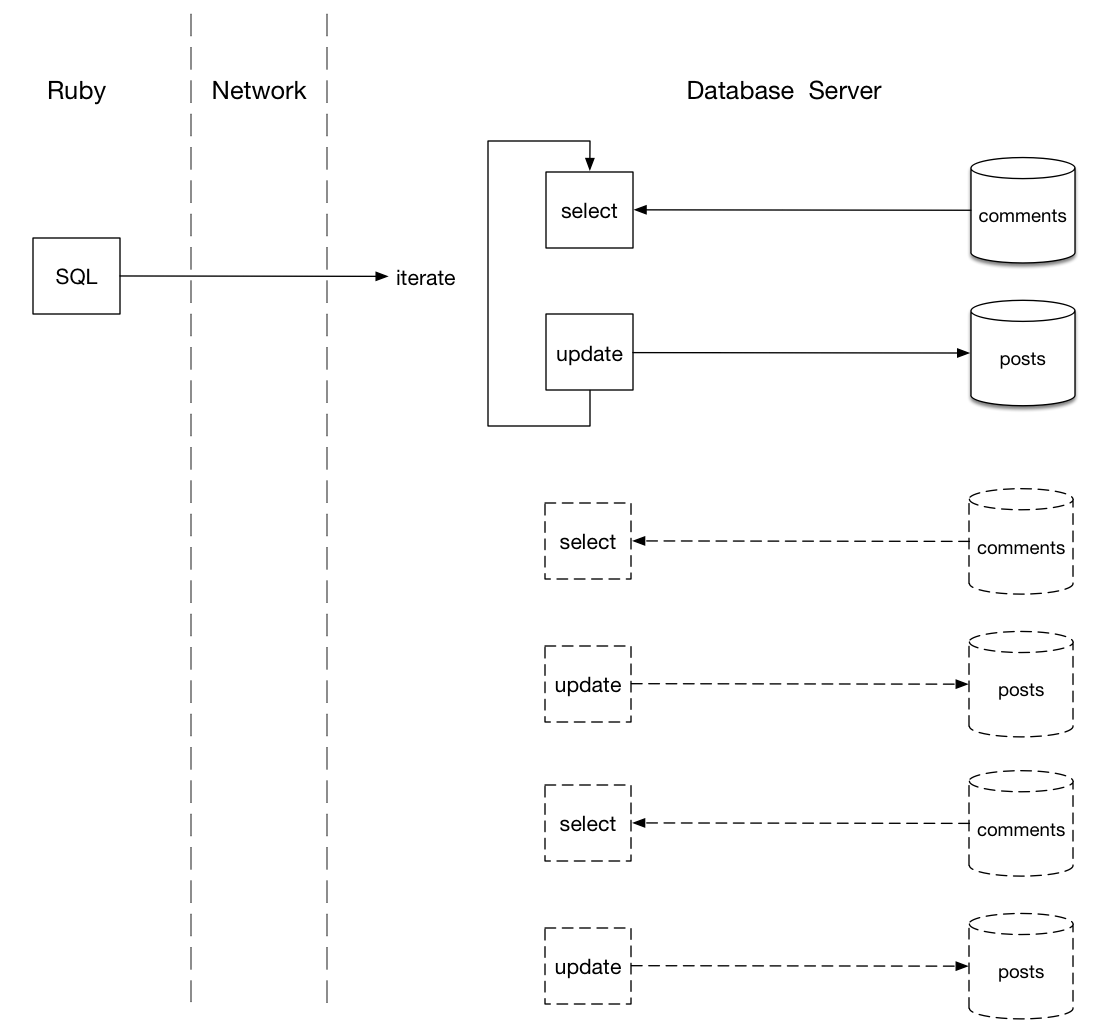
Using a SQL migration, my Ruby code sends a single SQL command to the database server, which is transmitted over the network to the database. Then, on the right, my database server performs the same iteration over the posts table, selecting the latest comment for each one.
This looks similar, but there’s a crucial difference: The iteration happens entirely inside the database server. No data needs to be packed, transmitted to the Ruby server and unpacked again. In fact, the C code performing the repeated SELECT statements has been compiled to native machine language and will run very quickly. Once it fetches the latest comment, it can directly update each post because the posts table is stored nearby on the same server’s hard drive, or even in memory.
Why Does the SQL Code Iterate?
You might wonder why I drew an iteration inside the database server above. After all, I sent the database a simple command containing 1 UPDATE statement and 1 SELECT statement. Why does my database need to execute the select over and over again?
The reason why is that my SQL code uses a correlated subquery, because the inner SELECT uses a value from the outer query. Here’s the SQL again:

Notice the inner SELECT statement refers to posts.id, a value from the surrounding UPDATE statement. This requires the database server to iterate over all of the posts, executing the inner select for each row. I’ll leave it as an exercise for the reader to rewrite this using an UPDATE-FROM statement, a JOIN or even Postgres window functions, which would avoid the repeated SELECTs.
However, remember if there are indexes on the columns in the comments table, the iteration selecting the latest comment for each post will be very fast. It will certainly be thousands of times faster than sending repeated SELECT and UPDATE SQL statements from your Ruby server over the network.
Do You Need to Learn SQL?
In reality I could have written this data migration using Ruby code. ActiveRecord provides a rich set of methods, even allowing for sophisticated queries employing subselects. And in the rare case when ActiveRecord can’t generate the SQL I need, I can always resort to using the underlying Arel Ruby library. In practice, it’s rare that you will actually need to write SQL code inside a Rails application.
Then why learn SQL? You should learn SQL because it will give you tremendous insight into how database servers actually work. You’ll learn what database servers can really do, and what they can’t. You won’t try to reinvent the wheel when you already have a server that uses algorithms more powerful and sophisticated that any you could write.
Use the database server for what it was designed to do: to solve your data problems. Whether you write SQL directly or use a tool like ActiveRecord to generate SQL automatically, perform the search, sort, or calculation you need right inside the database.
Don’t let your data out of the database until you need to… until you have just the values your application really needs.


